 MENU
MENU 

Eight papers by CSE researchers at UIST 2024

Researchers affiliated with CSE are presenting eight papers and four demos at the 2024 ACM Symposium on User Interface Software and Technology (UIST), a top international conference in the field of human-computer interaction. This year’s conference is taking place October 13-16 in Pittsburgh, PA.
Papers by CSE authors at UIST introduce a number of innovations in user interfaces, including a visual interactive explorer for assessing machine learning models, a novel program that provides live visual descriptions for blind and visually impaired individuals, and a virtual reality sound modification technique to improve accessibility for the deaf and hard-of-hearing.
The papers and demos appearing at the conference are as follows, with the names of CSE-affiliated authors in bold:
WorldScribe: Towards Context-Aware Live Visual Descriptions *Best Paper Award*
Ruei-Che Chang, Yuxuan Liu, Anhong Guo
Abstract: Automated live visual descriptions can aid blind people in understanding their surroundings with autonomy and independence. However, providing descriptions that are rich, contextual, and just-in-time has been a long-standing challenge in accessibility. In this work, we develop WorldScribe, a system that generates automated live real-world visual descriptions that are customizable and adaptive to users’ contexts: (i) WorldScribe’s descriptions are tailored to users’ intents and prioritized based on semantic relevance. (ii) WorldScribe is adaptive to visual contexts, e.g., providing consecutively succinct descriptions for dynamic scenes, while presenting longer and detailed ones for stable settings. (iii) WorldScribe is adaptive to sound contexts, e.g., increasing volume in noisy environments, or pausing when conversations start. Powered by a suite of vision, language, and sound recognition models, WorldScribe introduces a description generation pipeline that balances the tradeoffs between their richness and latency to support real-time use. The design of WorldScribe is informed by prior work on providing visual descriptions and a formative study with blind participants. Our user study and subsequent pipeline evaluation show that WorldScribe can provide real-time and fairly accurate visual descriptions to facilitate environment understanding that is adaptive and customized to users’ contexts. Finally, we discuss the implications and further steps toward making live visual descriptions more context-aware and humanized.

VIME: Visual Interactive Model Explorer for Identifying Capabilities and Limitations of Machine Learning Models for Sequential Decision-Making
Anindya Das Antar, Somayeh Molaei, Yan-Ying Chen, Matthew Lee, Nikola Banovic
Abstract: Ensuring that Machine Learning (ML) models make correct and meaningful inferences is necessary for the broader adoption of such models into high-stakes decision-making scenarios. Thus, ML model engineers increasingly use eXplainable AI (XAI) tools to investigate the capabilities and limitations of their ML models before deployment. However, explaining sequential ML models, which make a series of decisions at each timestep, remains challenging. We present Visual Interactive Model Explorer (VIME), an XAI toolbox that enables ML model engineers to explain decisions of sequential models in different “what-if” scenarios. Our evaluation with 14 ML experts, who investigated two existing sequential ML models using VIME and a baseline XAI toolbox to explore “what-if” scenarios, showed that VIME made it easier to identify and explain instances when the models made wrong decisions compared to the baseline. Our work informs the design of future interactive XAI mechanisms for evaluating sequential ML-based decision support systems.
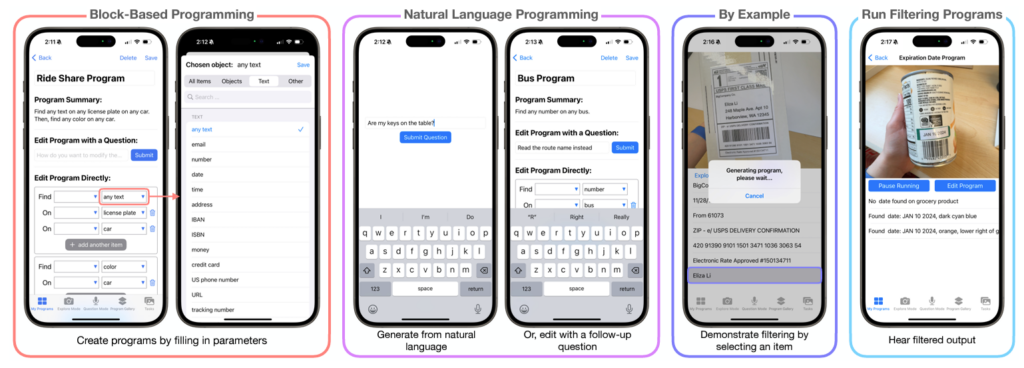
ProgramAlly: Creating Custom Visual Access Programs via Multi-Modal End-User Programming
Jaylin Herskovitz, Andi Xu, Rahaf Alharbi, Anhong Guo
Abstract: Existing visual assistive technologies are built for simple and common use cases, and have few avenues for blind people to customize their functionalities. Drawing from prior work on DIY assistive technology, this paper investigates end-user programming as a means for users to create and customize visual access programs to meet their unique needs. We introduce ProgramAlly, a system for creating custom filters for visual information, e.g., ‘find NUMBER on BUS’, leveraging three end-user programming approaches: block programming, natural language, and programming by example. To implement ProgramAlly, we designed a representation of visual filtering tasks based on scenarios encountered by blind people, and integrated a set of on-device and cloud models for generating and running these programs. In user studies with 12 blind adults, we found that participants preferred different programming modalities depending on the task, and envisioned using visual access programs to address unique accessibility challenges that are otherwise difficult with existing applications. Through ProgramAlly, we present an exploration of how blind end-users can create visual access programs to customize and control their experiences.
SoundModVR: Sound Modifications in Virtual Reality for Sound Accessibility (demo)
Xinyun Cao, Dhruv Jain
Abstract: Previous VR sound accessibility work have substituted sounds with visual or haptic output to increase VR accessibility for deaf and hard of hearing (DHH) people. However, deafness occurs on a spectrum, and many DHH people (e.g., those with partial hearing) can also benefit from manipulating audio (e.g., increasing volume at specific frequencies) instead of substituting it with another modality. In this demo paper, we present a toolkit that allows modifying sounds in VR to support DHH people. We designed and implemented 18 VR sound modification tools spanning four categories, including prioritizing sounds, modifying sound parameters, providing spatial assistance, and adding additional sounds. Evaluation of our tools with 10 DHH users across five diverse VR scenarios reveal that our toolkit can improve DHH users’ VR experience but could be further improved by providing more customization options and decreasing cognitive load. We then compiled a Unity toolkit and conducted a preliminary evaluation with six Unity VR developers. Preliminary insights show that our toolkit is easy to use but could be enhanced through modularization.
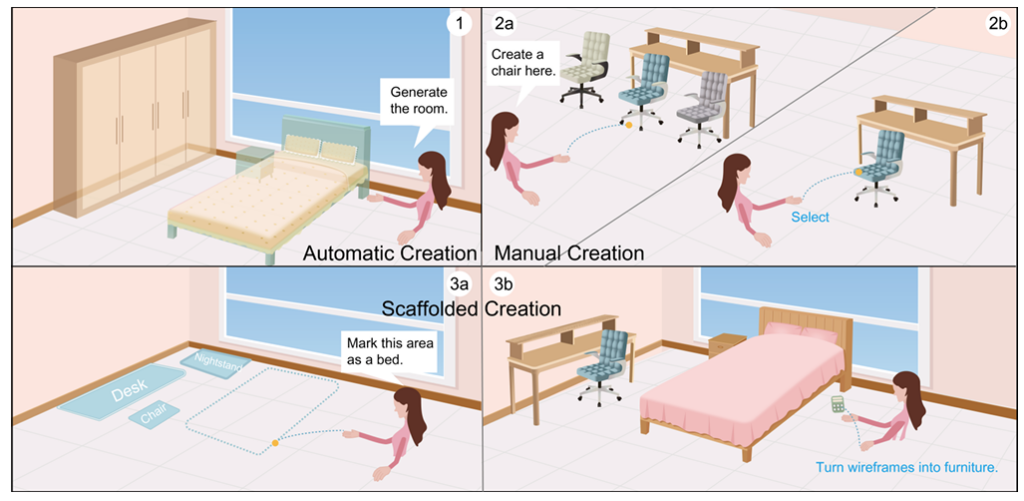
VRCopilot: Authoring 3D Layouts with Generative AI Models in VR
Lei Zhang, Jin Pan, Jacob Gettig, Steve Oney, Anhong Guo
Abstract: Immersive authoring provides an intuitive medium for users to create 3D scenes via direct manipulation in Virtual Reality (VR). Recent advances in generative AI have enabled the automatic creation of realistic 3D layouts. However, it is unclear how capabilities of generative AI can be used in immersive authoring to support fluid interactions, user agency, and creativity. We introduce VRCopilot, a mixed-initiative system that integrates pre-trained generative AI models into immersive authoring to facilitate human-AI co-creation in VR. VRCopilot presents multimodal interactions to support rapid prototyping and iterations with AI, and intermediate representations such as wireframes to augment user controllability over the created content. Through a series of user studies, we evaluated the potential and challenges in manual, scaffolded, and automatic creation in immersive authoring. We found that scaffolded creation using wireframes enhanced the user agency compared to automatic creation. We also found that manual creation via multimodal specification offers the highest sense of creativity and agency.
Feminist Interaction Techniques: Social Consent Signals to Deter NCIM Screenshots
Li Qiwei, Francesca Lameiro, Shefali Patel, Christi Isaula-Reyes, Eytan Adar, Eric Gilbert, Sarita Schoenebeck
Abstract: Non-consensual Intimate Media (NCIM) refers to the distribution of sexual or intimate content without consent. NCIM is common and causes significant emotional, financial, and reputational harm. We developed Hands-Off, an interaction technique for messaging applications that deters non-consensual screenshots. Hands-Off requires recipients to perform a hand gesture in the air, above the device, to unlock media—which makes simultaneous screenshotting difficult. A lab study shows that Hands-Off gestures are easy to perform and reduce non-consensual screenshots by 67%. We conclude by generalizing this approach and introduce the idea of Feminist Interaction Techniques (FIT), interaction techniques that encode feminist values and speak to societal problems, and reflect on FIT’s opportunities and limitations.
SonoHaptics: An Audio-Haptic Cursor for Gaze-Based Object Selection in XR
Hyunsung Cho, Naveen Sendhilnathan, Michael Nebeling, Tianyi Wang, Purnima Padmanabhan, Jonathan Browder, David Lindlbauer, Tanya R. Jonker, Kashyap Todi
Abstract: We introduce SonoHaptics, an audio-haptic cursor for gaze-based 3D object selection. SonoHaptics addresses challenges around providing accurate visual feedback during gaze-based selection in Extended Reality (XR), e.g., lack of world-locked displays in no- or limited-display smart glasses and visual inconsistencies. To enable users to distinguish objects without visual feedback, SonoHaptics employs the concept of cross-modal correspondence in human perception to map visual features of objects (color, size, position, material) to audio-haptic properties (pitch, amplitude, direction, timbre). We contribute data-driven models for determining cross-modal mappings of visual features to audio and haptic features, and a computational approach to automatically generate audio-haptic feedback for objects in the user’s environment. SonoHaptics provides global feedback that is unique to each object in the scene, and local feedback to amplify differences between nearby objects. Our comparative evaluation shows that SonoHaptics enables accurate object identification and selection in a cluttered scene without visual feedback.
Auptimize: Optimal Placement of Spatial Audio Cues for Extended Reality
Hyunsung Cho, Alexander Wang, Divya Kartik, Emily Liying Xie, Yukang Yan, David Lindlbauer
Abstract: Spatial audio in Extended Reality (XR) provides users with better awareness of where virtual elements are placed, and efficiently guides them to events such as notifications, system alerts from different windows, or approaching avatars. Humans, however, are inaccurate in localizing sound cues, especially with multiple sources due to limitations in human auditory perception such as angular discrimination error and front-back confusion. This decreases the efficiency of XR interfaces because users misidentify from which XR element a sound is coming. To address this, we propose Auptimize, a novel computational approach for placing XR sound sources, which mitigates such localization errors by utilizing the ventriloquist effect. Auptimize disentangles the sound source locations from the visual elements and relocates the sound sources to optimal positions for unambiguous identification of sound cues, avoiding errors due to inter-source proximity and front-back confusion. Our evaluation shows that Auptimize decreases spatial audio-based source identification errors compared to playing sound cues at the paired visual-sound locations. We demonstrate the applicability of Auptimize for diverse spatial audio-based interactive XR scenarios.
Towards Music-Aware Virtual Assistants
Alexander Wang, David Lindlbauer, Chris Donahue
Abstract: We propose a system for modifying spoken notifications in a manner that is sensitive to the music a user is listening to. Spoken notifications provide convenient access to rich information without the need for a screen. Virtual assistants see prevalent use in hands-free settings such as driving or exercising, activities where users also regularly enjoy listening to music. In such settings, virtual assistants will temporarily mute a user’s music to improve intelligibility. However, users may perceive these interruptions as intrusive, negatively impacting their music-listening experience. To address this challenge, we propose the concept of music-aware virtual assistants, where speech notifications are modified to resemble a voice singing in harmony with the user’s music. We contribute a system that processes user music and notification text to produce a blended mix, replacing original song lyrics with the notification content. In a user study comparing musical assistants to standard virtual assistants, participants expressed that musical assistants fit better with music, reduced intrusiveness, and provided a more delightful listening experience overall.