 MENU
MENU 

Finding meaning in varied data
Jie Song devised a method to combine summarized datasets that group information by incompatible units.
CSE grad student Jie Song earned the runner up Best Paper Award at the 2018 Extending Database Technology conference for her paper “GeoAlign: Interpolating Aggregates over Unaligned Partitions.” Song, working with Bernard A. Galler Collegiate Professor of Electrical Engineering and Computer Science H.V. Jagadish and Prof. Danai Koutra, devised a method to combine summarized datasets that group information by incompatible units.
Big organizations that gather lots of data, from companies to government agencies, typically format that data to meet their specific needs, meaning the way it is structured varies from group to group. On top of that, they typically make this data public only as geographic or time-period summaries to protect the privacy of individuals in the list.
Much of the data from these varied sources could provide new insights to important social problems when taken together – but until now it has been challenging to neatly reformat and combine data sets that are structured very differently or aggregated with different units (ZIP code vs. county, or even geography vs. time).
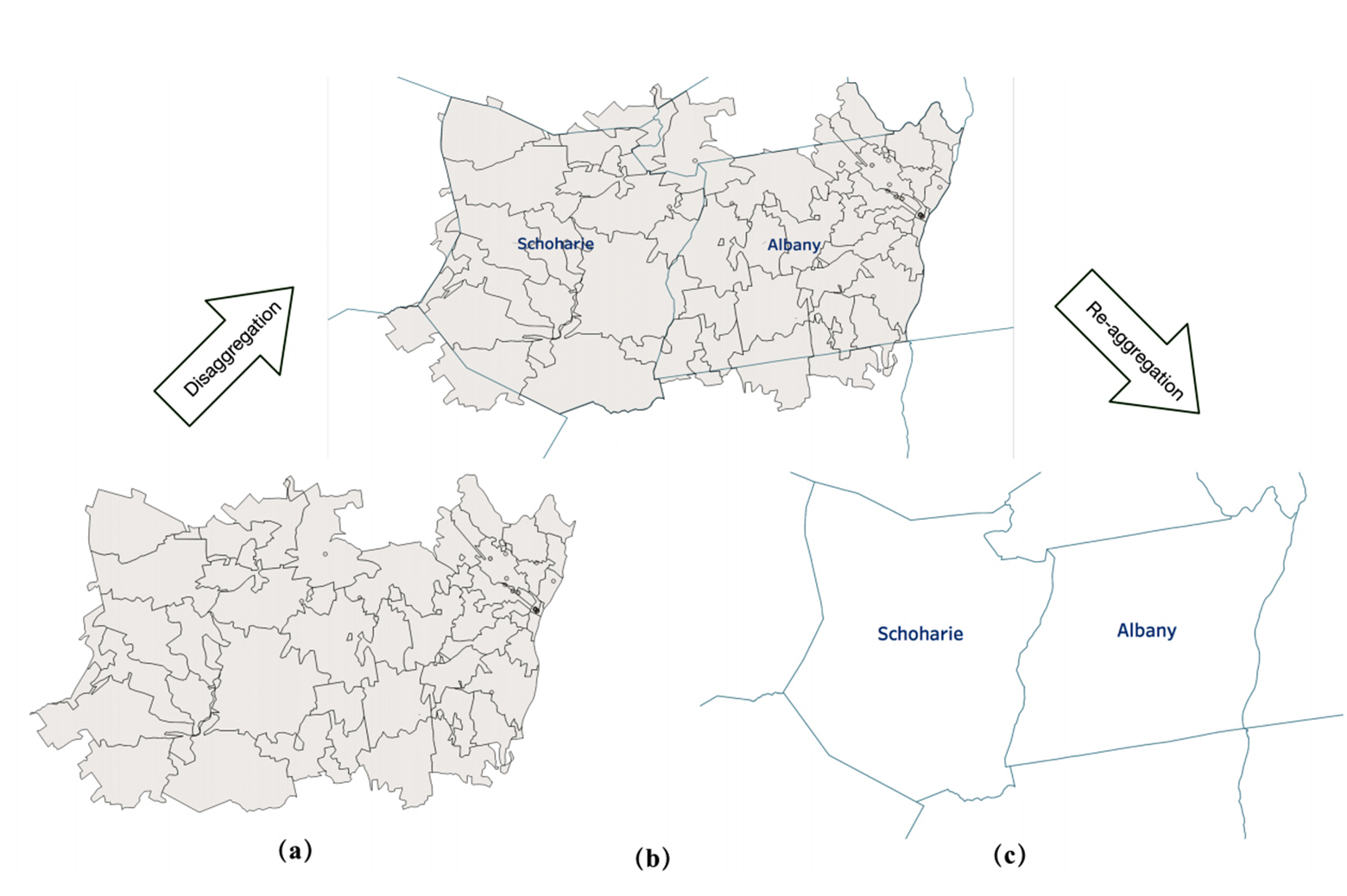
 Enlarge
EnlargeTo solve this the researchers devised GeoAlign, an algorithm that converts an aggregate to desired target units. This solution is adaptive to new attributes without needing knowledge of the spatial properties of the original and target units. Experiments show that GeoAlign can easily be extended to realign aggregate data in multi-dimensional space for general use. Experiments on real, public government datasets show that GeoAlign achieves equal or better accuracy than the leading state-of-the-art approach without sacrificing scalability and robustness. It also makes better predictions in a reasonably short time, with a runtime that scales linearly with the number of units in the source and target datasets.