 MENU
MENU 

Four papers by CSE researchers at OSDI 2024

Four papers authored by researchers affiliated with CSE have been accepted for presentation at the 2024 USENIX Symposium on Operating Systems Design and Implementation (OSDI). A leading international venue for new research in computer systems, OSDI brings together professionals from both academia and industry to discuss the latest innovations in the systems space, from operating systems to cloud computing and beyond. The 2024 iteration of the conference is taking place in Santa Clara, CA from July 10-12.
With just 44 papers overall accepted by the conference this year, OSDI is extremely selective of the research it chooses for publication, making CSE’s four papers—10% of the total volume—a remarkable achievement.
New research by CSE authors covers topics including memory allocation for CXL-based memory, in-network machine learning, distributed protocol proofs, and more. The following papers are being presented at the conference, with the names of CSE researchers in bold:
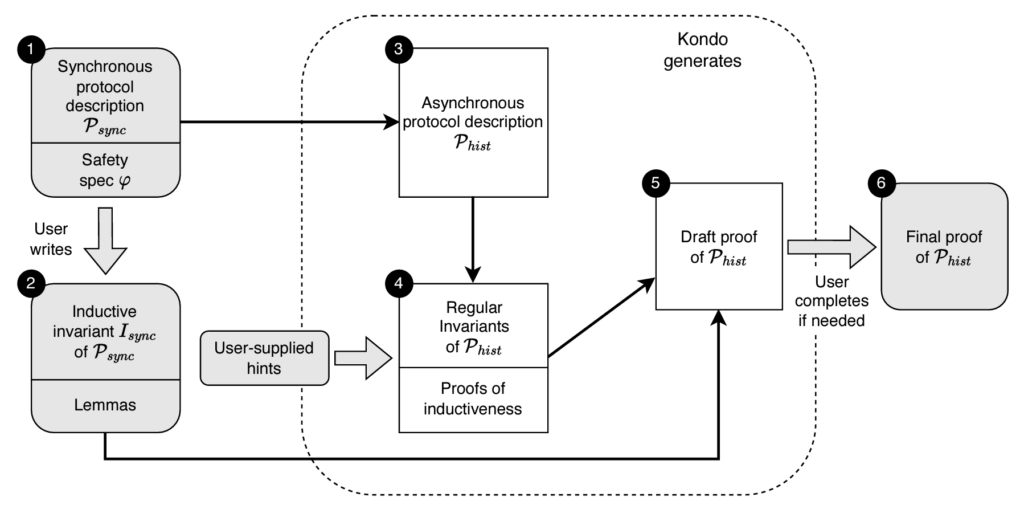
“Inductive Invariants That Spark Joy: Using Invariant Taxonomies to Streamline Distributed Protocol Proofs”
Tony Nuda Zhang, Travis Hance, Manos Kapritsos, Tej Chajed, Bryan Parno
Abstract: Proving the correctness of a distributed protocol is a challenging endeavor. Central to this task is finding an inductive invariant for the protocol. Currently, automated invariant inference algorithms require developers to describe protocols using a restricted logic. If the developer wants to prove a protocol expressed without these restrictions, they must devise an inductive invariant manually.
We propose an approach that simplifies and partially automates finding the inductive invariant of a distributed protocol, as well as proving that it really is an invariant. The key insight is to identify an invariant taxonomy that divides invariants into Regular Invariants, which have one of a few simple low-level structures, and Protocol Invariants, which capture the higher-level host relationships that make the protocol work.
Building on the insight of this taxonomy, we describe the Kondo methodology for proving the correctness of a distributed protocol modeled as a state machine. The developer first manually devises the Protocol Invariants by proving a synchronous version of the protocol correct. In this simpler version, sends and receives are replaced with atomic variable assignments. The Kondo tool then automatically generates the asynchronous protocol description, Regular Invariants, and proofs that the Regular Invariants are inductive on their own. Finally, Kondo combines these with the synchronous proof into a draft proof of the asynchronous protocol, which may then require a small amount of user effort to complete. Our evaluation shows that Kondo reduces developer effort for a wide variety of distributed protocols.
“IronSpec: Increasing the Reliability of Formal Specifications”
Eli Goldweber, Weixin Yu, Seyed Armin Vakil Ghahani, Manos Kapritsos
Abstract: The guarantees of formally verified systems are only as strong as their trusted specifications (specs). As observed by previous studies, bugs in formal specs invalidate the assurances that proofs provide. Unfortunately, specs—by their very nature—cannot be proven correct. Currently, the only way to identify spec bugs is by careful, manual inspection.
In this paper we introduce IronSpec, a framework of automatic and manual techniques to increase the reliability of formal specifications. IronSpec draws inspiration from classical software testing practices, which we adapt to the realm of formal specs. IronSpec facilitates spec testing with automated sanity checking, a methodology for writing SpecTesting Proofs (STPs), and automated spec mutation testing.
We evaluate IronSpec on 14 specs, including six specs of real-world verified codebases. Our results show that IronSpec is effective at flagging discrepancies between the spec and the developer’s intent, and has led to the discovery of ten specification bugs across all six real-world verified systems.
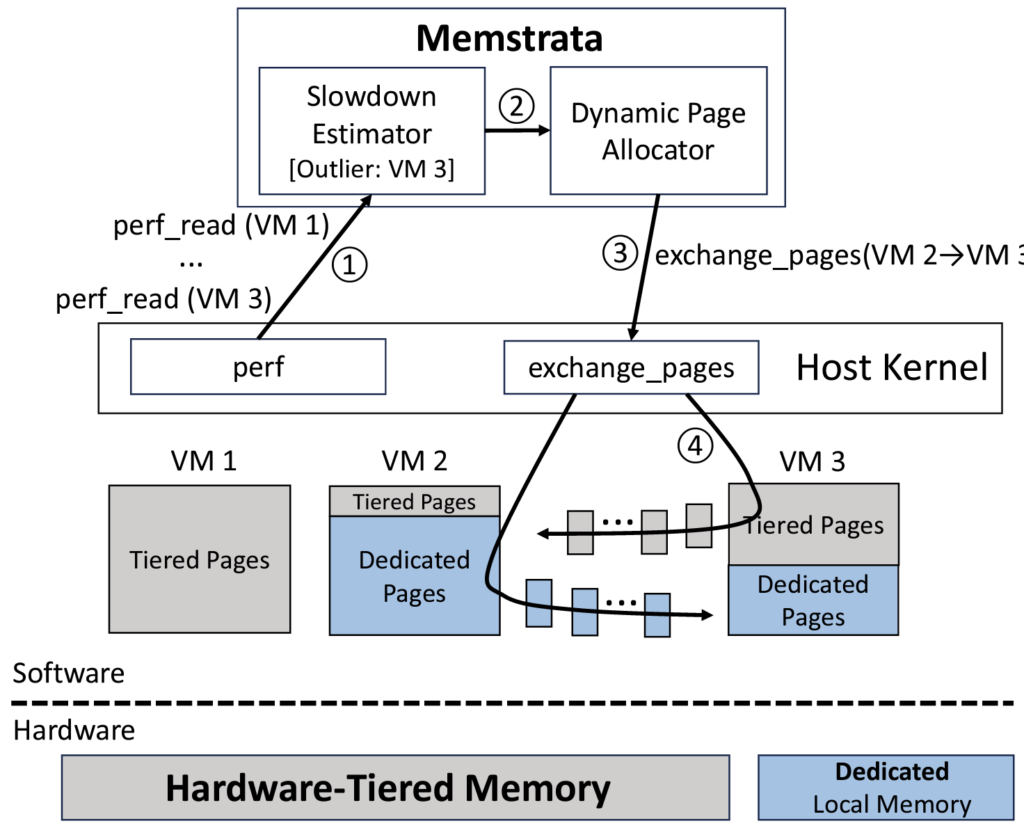
“Managing Memory Tiers with CXL in Virtualized Environments”
Yuhong Zhong, Daniel S. Berger, Carl Waldspurger, Ryan Wee, Ishwar Agarwal, Rajat Agarwal, Frank Hady, Karthik Kumar, Mark D. Hill, Mosharaf Chowdhury, Asaf Cidon
Abstract: Cloud providers seek to deploy CXL-based memory to increase aggregate memory capacity, reduce costs, and lower carbon emissions. However, CXL accesses incur higher latency than local DRAM. Existing systems use software to manage data placement across memory tiers at page granularity. Cloud providers are reluctant to deploy software-based tiering due to high overheads in virtualized environments. Hardware-based memory tiering could place data at cacheline granularity, mitigating these drawbacks. However, hardware is oblivious to application-level performance.
We propose combining hardware-managed tiering with software-managed performance isolation to overcome the pitfalls of either approach. We introduce Intel® Flat Memory Mode, the first hardware-managed tiering system for CXL. Our evaluation on a full-system prototype demonstrates that it provides performance close to regular DRAM, with no more than 5% degradation for more than 82% of workloads. Despite such small slowdowns, we identify two challenges that can still degrade performance by up to 34% for “outlier” workloads: (1) memory contention across tenants, and (2) intra-tenant contention due to conflicting access patterns.
To address these challenges, we introduce Memstrata, a lightweight multi-tenant memory allocator. Memstrata employs page coloring to eliminate inter-VM contention. It improves performance for VMs with access patterns that are sensitive to hardware tiering by allocating them more local DRAM using an online slowdown estimator. In multi-VM experiments on prototype hardware, Memstrata is able to identify performance outliers and reduce their degradation from above 30% to below 6%, providing consistent performance across a wide range of workloads.
“Caravan: Practical Online Learning of In-Network ML Models with Labeling Agents”
Qizheng Zhang, Ali Imran, Enkeleda Bardhi, Tushar Swamy, Nathan Zhang, Muhammad Shahbaz, Kunle Olukotun
Abstract: Recent work on in-network machine learning (ML) anticipates offline models to operate well in modern networking environments. However, upon deployment, these models struggle to cope with fluctuating traffic patterns and network conditions and, therefore, must be validated and updated frequently in an online fashion.
This paper presents CARAVAN, a practical online learning system for in-network ML models. We tackle two primary challenges in facilitating online learning for networking: (a) the automatic labeling of evolving traffic and (b) the efficient monitoring and detection of model performance degradation to trigger retraining. CARAVAN repurposes existing systems (e.g., heuristics, access control lists, and foundation models)— not directly suitable for such dynamic environments—into high-quality labeling sources for generating labeled data for online learning. CARAVAN also introduces a new metric, accuracy proxy, to track model degradation and potential drift to efficiently trigger retraining. Our evaluations show that CARAVAN’s labeling strategy enables in-network ML models to closely follow the changes in the traffic dynamics with a 30.3% improvement in F1 score (on average), compared to offline models. Moreover, CARAVAN sustains comparable inference accuracy to that of a continuous-learning system while consuming 61.3% less GPU compute time (on average) via accuracy proxy and retraining triggers.