 MENU
MENU 

Nine papers by CSE researchers at NAACL 2025
Researchers affiliated with CSE are presenting a total of nine papers at the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL). A top conference in the field of computational linguistics, NAACL brings together experts in natural language processing and related areas to discuss the latest findings and foster collaboration, with a regional focus in North, Central, and South America. This year’s event is taking place in Albuquerque, NM, on April 29-May 4.
New research by CSE authors appearing at NAACL 2025 focuses on a range of topics, including cultural image captioning, gender bias in language models, and multilingual deception detection in AI-generated reviews. The papers being presented are as follows, the names of authors affiliated with CSE in bold:
The Power of Many: Multi-Agent Multimodal Models for Cultural Image Captioning
Longju Bai, Angana Borah, Oana Ignat, Rada Mihalcea
Abstract: Large Multimodal Models (LMMs) exhibit impressive performance across various multimodal tasks. However, their effectiveness in cross-cultural contexts remains limited due to the predominantly Western-centric nature of most data and models. Conversely, multi-agent models have shown significant capability in solving complex tasks. Our study evaluates the collective performance of LMMs in a multi-agent interaction setting for the novel task of cultural image captioning. Our contributions are as follows: (1) We introduce MosAIC, a Multi-Agent framework to enhance cross-cultural Image Captioning using LMMs with distinct cultural personas; (2) We provide a dataset of culturally enriched image captions in English for images from China, India, and Romania across three datasets: GeoDE, GD-VCR, CVQA; (3) We propose a culture-adaptable metric for evaluating cultural information within image captions; and (4) We show that the multi-agent interaction outperforms single-agent models across different metrics, and offer valuable insights for future research.

Babysit A Language Model From Scratch: Interactive Language Learning by Trials and Demonstrations
Ziqiao Ma, Zekun Wang, Joyce Chai
Abstract: Humans are efficient language learners and inherently social creatures. Our language development is largely shaped by our social interactions, for example, the demonstration and feedback from caregivers. Contrary to human language learning, recent advancements in large language models have primarily adopted a non-interactive training paradigm, and refined pre-trained models through feedback afterward. In this work, we explore how corrective feedback from interactions influences neural language acquisition from scratch through systematically controlled experiments, assessing whether it contributes to word learning efficiency in language models. We introduce a trial-and-demonstration (TnD) learning framework that incorporates three distinct components: student trials, teacher demonstrations, and a reward conditioned on language competence at various developmental stages. Our experiments reveal that the TnD approach accelerates word acquisition for student models of equal and smaller numbers of parameters, and we highlight the significance of both trials and demonstrations. We further show that the teacher’s choices of words influence students’ word-specific learning efficiency, and a practice-makes-perfect effect is evident by a strong correlation between the frequency of words in trials and their respective learning curves. Our findings suggest that interactive language learning, with teacher demonstrations and active trials, can facilitate efficient word learning in language models.
Examining Spanish Counseling with MIDAS: A Motivational Interviewing Dataset in Spanish
Aylin Gunal, Bowen Yi, John D. Piette, Rada Mihalcea, Verónica Pérez-Rosas
Abstract: Cultural and language factors significantly influence counseling, but Natural Language Processing research has not yet examined whether the findings of conversational analysis for counseling conducted in English apply to other languages. This paper presents a first step towards this direction. We introduce MIDAS (Motivational Interviewing Dataset in Spanish), a counseling dataset created from public video sources that contains expert annotations for counseling reflections and questions. Using this dataset, we explore language-based differences in counselor behavior in English and Spanish and develop classifiers in monolingual and multilingual settings, demonstrating its applications in counselor behavioral coding tasks.
Causally Modeling the Linguistic and Social Factors that Predict Email Response
Yinuo Xu, Hong Chen, Sushrita Rakshit, Aparna Ananthasubramaniam, Omkar Yadav, Mingqian Zheng, Michael Jiang, Lechen Zhang, Bowen Yi, Kenan Alkiek, Abraham Israeli, Bangzhao Shu, Hua Shen, Jiaxin Pei, Haotian Zhang, Miriam Schirmer, David Jurgens
Abstract: Email is a vital conduit for human communication across businesses, organizations, and broader societal contexts. In this study, we aim to model the intents, expectations, and responsiveness in email exchanges. To this end, we release SIZZLER, a new dataset containing 1800 emails annotated with nuanced types of intents and expectations. We benchmark models ranging from feature-based logistic regression to zero-shot prompting of large language models. Leveraging the predictive model for intent, expectations, and 14 other features, we analyze 11.3M emails from GMANE to study how linguistic and social factors influence the conversational dynamics in email exchanges. Through our causal analysis, we find that the email response rates are influenced by social status, argumentation, and in certain limited contexts, the strength of social connection.

Causally Testing Gender Bias in LLMs: A Case Study on Occupational Bias
Yuen Chen, Vethavikashini Chithrra Raghuram, Justus Mattern, Rada Mihalcea, Zhijing Jin
Abstract: Generated texts from large language models (LLMs) have been shown to exhibit a variety of harmful, human-like biases against various demographics. These findings motivate research efforts aiming to understand and measure such effects. This paper introduces a causal formulation for bias measurement in generative language models. Based on this theoretical foundation, we outline a list of desiderata for designing robust bias benchmarks. We then propose a benchmark called OccuGender, with a bias-measuring procedure to investigate occupational gender bias. We test several state-of-the-art open-source LLMs on OccuGender, including Llama, Mistral, and their instruction-tuned versions. The results show that these models exhibit substantial occupational gender bias. Lastly, we discuss prompting strategies for bias mitigation and an extension of our causal formulation to illustrate the generalizability of our framework.
MAiDE-up: Multilingual Deception Detection of AI-generated Hotel Reviews
Oana Ignat, Xiaomeng Xu, Rada Mihalcea
Abstract: Deceptive reviews are becoming increasingly common, especially given the increase in performance and the prevalence of LLMs. While work to date has addressed the development of models to differentiate between truthful and deceptive human reviews, much less is known about the distinction between real reviews and AI-authored fake reviews. Moreover, most of the research so far has focused primarily on English, with very little work dedicated to other languages. In this paper, we compile and make publicly available the MAiDE-up dataset, consisting of 10,000 real and 10,000 AI-generated fake hotel reviews, balanced across ten languages. Using this dataset, we conduct extensive linguistic analyses to (1) compare the AI fake hotel reviews to real hotel reviews, and (2) identify the factors that influence the deception detection model performance. We explore the effectiveness of several models for deception detection in hotel reviews across three main dimensions: sentiment, location, and language. We find that these dimensions influence how well we can detect AI-generated fake reviews.
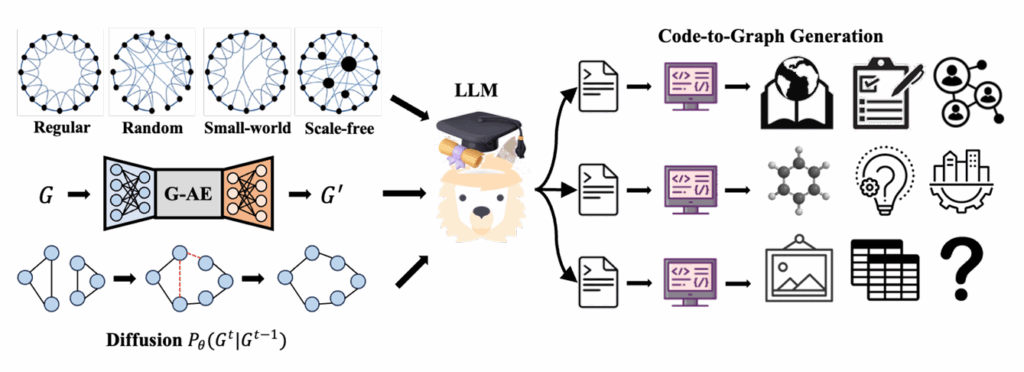
Demystifying the Power of Large Language Models in Graph Generation
Yu Wang, Ryan A. Rossi, Namyong Park, Nesreen K. Ahmed, Danai Koutra, Franck Dernoncourt, Tyler Derr
Abstract: Despite the unprecedented success of applying Large Language Models (LLMs) to graph discriminative tasks such as node classification and link prediction, its potential for graph structure generation remains largely unexplored. To fill this crucial gap, this paper presents a systematic investigation into the capability of LLMs for graph structure generation. Specifically, we design prompts triggering LLMs to generate codes that optimize network properties by injecting domain expertise from network science. Since graphs in different domains exhibit unique structural properties captured by various metrics (e.g., clustering coefficient capturing triangles in social networks while squares reflecting road segments in transportation networks), we first evaluate the capability of LLMs to generate graphs satisfying each structural property in different domains. After that, we select the optimal property configurations and benchmark the graph structure generation performance of LLMs against established graph generative models across multiple domains. Our findings shed light on generating graph structures from an LLM perspective.
Sociodemographic Prompting is Not Yet an Effective Approach for Simulating Subjective Judgments with LLMs
Huaman Sun, Jiaxin Pei, Minje Choi, David Jurgens
Abstract: Human judgments are inherently subjective and are actively affected by personal traits such as gender and ethnicity. While Large LanguageModels (LLMs) are widely used to simulate human responses across diverse contexts, their ability to account for demographic differences in subjective tasks remains uncertain. In this study, leveraging the POPQUORN dataset, we evaluate nine popular LLMs on their ability to understand demographic differences in two subjective judgment tasks: politeness and offensiveness. We find that in zero-shot settings, most models’ predictions for both tasks align more closely with labels from White participants than those from Asian or Black participants, while only a minor gender bias favoring women appears in the politeness task. Furthermore, sociodemographic prompting does not consistently improve and, in some cases, worsens LLMs’ ability to perceive language from specific sub-populations. These findings highlight potential demographic biases in LLMs when performing subjective judgment tasks and underscore the limitations of sociodemographic prompting as a strategy to achieve pluralistic alignment.
MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Scientific Workflows
Xingjian Zhang, Yutong Xie, Jin Huang, Jinge Ma, Zhaoying Pan, Qijia Liu, Ziyang Xiong, Tolga Ergen, Dongsub Shim, Honglak Lee, Qiaozhu Mei
Abstract: Scientific innovation relies on detailed workflows, which include critical steps such as contextualizing literature, generating ideas, validating ideas, interpreting results, and planning new research. Scientific publications that document these workflows are extensive and unstructured, making it difficult to effectively navigate and explore the space of scientific innovation. To meet this challenge, we introduce MASSW, a comprehensive dataset of MultiAspect Summarization of Scientific Workflows. MASSW includes more than 152,000 peer-reviewed publications from 17 leading computer science conferences spanning the past 50 years. Using Large Language Models (LLMs), we automatically extract five core aspects from these publications– context, key idea, method, outcome, and projected impact– which correspond to five key steps in a research workflow.. We show that these LLM-extract summaries have a comparable quality to human annotations, and they facilitate a variety of downstream tasks, corresponding to different types of predictions and recommendations along the scientific workflow. Overall, MASSW demonstrates decent utility as a pre-computed and trustful resource for the AI4Science community to create and benchmark a wide-range of new AI methods for optimizing scientific workflows and fostering scientific innovation.