 MENU
MENU 

NSF backs U-M research to enhance reliability of distributed systems


From email servers to the cloud, distributed systems have quickly become an integral part of our everyday lives. In this era of rapidly escalating data use, the demands on these systems are higher than ever, and lapses in reliability can have drastic effects.
Associate Professor Ryan Huang and Assistant Professor Xinyu Wang have received $750,000 in National Science Foundation (NSF) funding to tackle this issue. The aim of their project, titled Synthesizing Semantic Checkers for Runtime Verification of Production Distributed Systems, is to identify and resolve what they term silent failures in distributed systems, which occur when the semantic guarantees built into them are violated without the user knowing.
Huang and Wang’s proposed solution utilizes already available test cases to perform runtime verification on these systems and continuously check for such failures. Their framework ensures that the distributed systems we rely on in multiple facets of our lives are functioning as we expect them to.
“Our society is increasingly dependent on distributed systems to provide a variety of services,” said Huang. “Our goal is to enhance the reliability of these systems and make sure they’re behaving the way they’re supposed to for the end user.”
Distributed systems, from cloud storage systems such as Google Drive and Dropbox to messaging services such as Gmail or Slack, rely on a network of multiple computer nodes to process large volumes of data. To the end user, however, this complex network of computers is largely invisible.
“The software behind these systems is run through data centers across the world, which are made up of thousands, tens of thousands, and even millions of machines,” said Huang. “These online services present a single consistent interface, but behind the scenes there are many, many machines powering them.”

As the number of computer nodes in a system increases, so too does the potential for errors. Small bugs in a system, whether malicious or accidental, can cause data to effectively slip through the cracks, and the end user is none the wiser. These breakdowns of the semantic guarantees that make up these systems give rise to the silent failures that Huang and Wang are working to address.
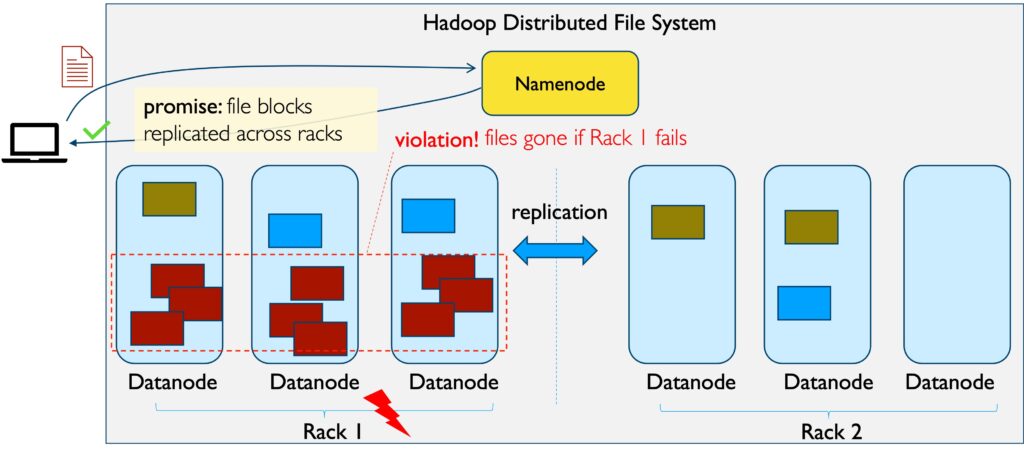
“With a cloud storage service such as Dropbox, for instance, the guarantee is that when you upload a file, that file will be replicated on different machines so that even if one machine goes down, your file will not be lost,” said Huang.
A silent failure in this instance could occur if the file does not replicate when uploaded, and the system fails to report the error. The service and the user alike proceed under the false assumption that the guarantee has been upheld and the file has been replicated, even when this is not the case.
These lapses, which often go undetected, can lead to severe consequences over time, resulting in outages, data losses, and wasted resources.
Huang and Wang’s proposed framework utilizes runtime verification, an approach that monitors a system continuously to make sure it is operating correctly within its defined parameters. And while such tools have seen broad adoption in embedded and physical systems, very few distributed systems employ them.
“Each distributed system has many different functionalities and is made up of hundreds or thousands of APIs,” said Huang. “They have a very nuanced and complex set of rules determining what constitutes correct behavior. This makes manually writing runtime checkers for these systems almost impossible.”
Huang and Wang’s scheme overcomes this obstacle by automatically creating runtime checkers to monitor distributed systems using test cases written by the system developers themselves. These test cases outline a detailed scenario or sequence of actions used to determine if a specific functionality within a distributed system is working as expected.
“Test cases already encode some knowledge about how a system should behave,” said Huang. “So we’re not starting from zero; we are using what the developer has already provided as a foundation for building an accurate runtime checker.”
Using these test cases, Huang and Wang plan to build a framework for automatically converting test cases into semantic checkers, circumventing the need for manually written checkers and making runtime verification a more feasible and easily deployable tool in any distributed system.
This project is an extension of Huang’s previous work, including his development of Oathkeeper, a runtime verification tool that automatically infers semantic rules in distributed systems based on past failures and uses these rules to detect new failures. Leveraging his previous work in this area along with Wang’s expertise in program synthesis, the duo aims to create an end-to-end solution that more easily checks for and prevents silent failures, protecting the data of end users.
“We want to build on and enhance this framework to make a tool that is practical and easy for developers to use,” said Huang. “The end goal is to make sure the online services we all rely on are reliable and functioning correctly continuously.”