 MENU
MENU 

Research on human biases in AI learning earns best student paper award
The project, which received a best paper award, demonstrated that a certain bias in humans who train intelligent agents significantly reduced the effectiveness of the training.
A team of researchers working to more effectively train autonomous agents earned the Pragnesh Jay Modi Best Student Paper at the International Conference On Autonomous Agents and Multi-Agent Systems (AAMAS 2020). Led by second-year PhD student Divya Ramesh, the project demonstrated that a certain bias in human trainers significantly reduced the effectiveness of an agent’s learning.
Intelligent agents promise to save us time spent on repetitive, menial tasks, freeing us up for more creative and meaningful work. But to do that they need to be able to work with us effectively. That means that they must be attuned to a user’s strengths and weaknesses, and able to navigate our complex working environments.
“Personalization of such agents is a key requirement,” Ramesh says in her virtual presentation. “We live in complex and dynamic environments, and if these agents are to be truly useful, they should be able to interact with us in these same environments and make decisions under uncertainty. Hence, adaptability of agents is another prerequisite.”
Researchers have developed a powerful tool to give agents these abilities. Called reinforcement learning (RL), the technique trains agents through interactions with their environments. Some work in RL makes use of user input in the form of feedback mapped to numerical reward signals. For example, the team writes, in domains like autonomous driving, where the cost of learning by trial-and-error is too expensive, there have been attempts to use human drivers’ actions as rewards and punishments to design robust self-driving algorithms.
These techniques, called “human-in-the-loop” RL, make use of hundreds of remote workers to give feedback to an agent’s performance on various tasks. It’s these trainers who can turn out to be a weak point in the agent’s learning pipeline.
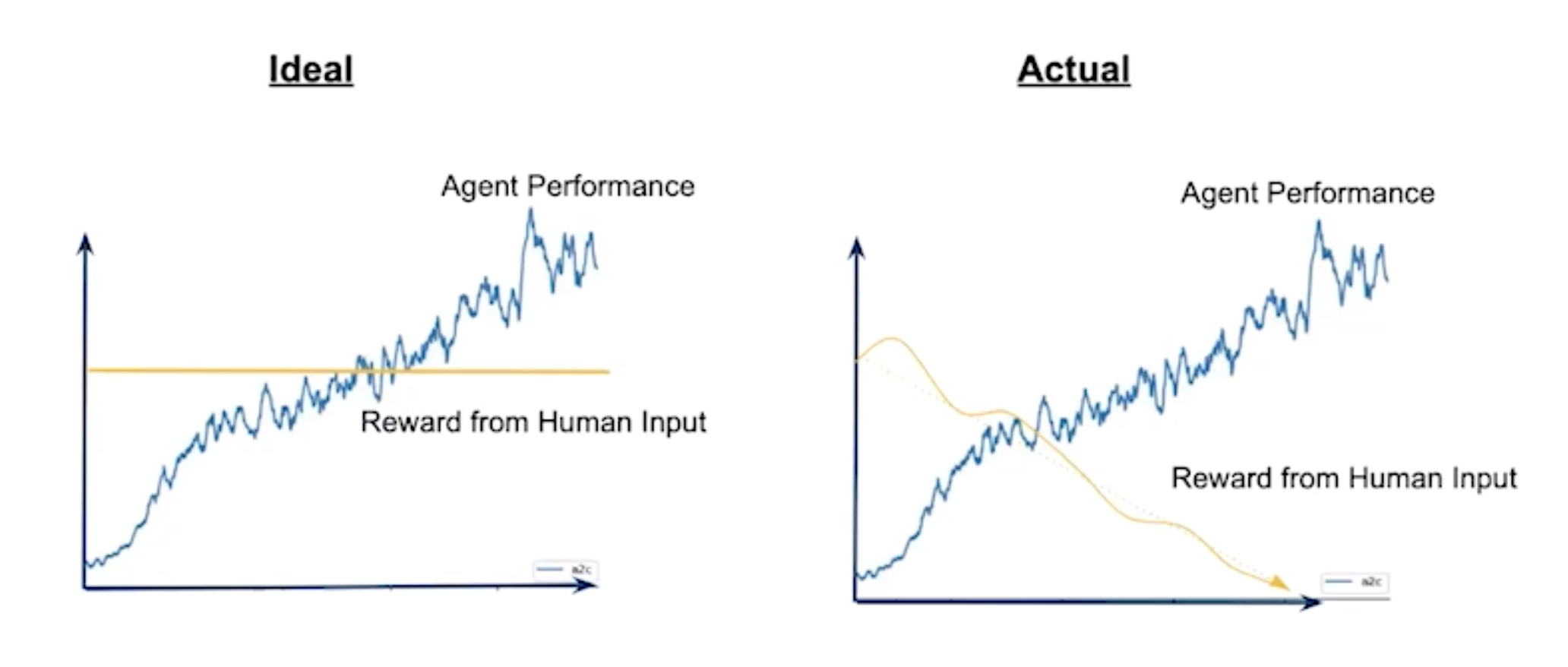
The paper’s authors highlighted the negative impacts of a cognitive bias called the contrast effect. Essentially, this effect describes how surrounding context influences a person’s judgment.

 Enlarge
EnlargeThe team designed a set of studies involving 900 participants from Amazon Mechanical Turk who were asked to give feedback to RL agents that played several Atari games. They demonstrated that participants tended to significantly underrate an agent’s actions after being exposed to an agent of higher competence on the same task. This meant that many agents were being scored too low, which directly impacts how they learn from the exercise.
“Even though evidence of these errors has been observed in human-agent interactions previously,” says Ramesh, “their existence has not been verified.”
The impact is not negligible – to understand its significance, the researchers simulated trainers that underrate an agent’s actions based on past performance. This creates a systematically skewed feedback signal, and the results showed that agents trained this way suffered up to a 98% performance loss.
 Enlarge
Enlarge“The greater the change in feedback, the worse the agent learns,” Ramesh says. “Our work calls for careful considerations of stability and variance characteristics of RL algorithms when interfacing humans and agents.
The authors hope that providing this verification can inform the design of human-agent interactions going forward. The paper, titled “Yesterday’s Reward is Today’s Punishment: Contrast Effects in Human Feedback to Reinforcement Learning Agents,” was co-authored by University of Michigan researchers Anthony Liu, Jean Song, Andres Echeverria, and Prof. Walter Lasecki, as well as Nicholas R. Waytowich from the Army Research Laboratory.