 MENU
MENU 

Seven papers by CSE researchers presented at AAAI 2021
Twelve students and faculty co-authored papers spanning several key application areas for AI.
Researchers at U-M CSE have been accepted to present seven papers at the 2021 Association for the Advancement of AI (AAAI) Conference, one of the top conferences in the field of artificial intelligence. Twelve students and faculty described their projects spanning several key application areas for AI, including healthcare, finance, games, and robotics.
Learn more about the papers:
 Enlarge
EnlargeEfficient Querying for Cooperative Probabilistic Commitments
Qi Zhang (University of South Carolina), Edmund Durfee (University of Michigan), Satinder Singh (University of Michigan)
Multiagent systems can use commitments as the core of a general coordination infrastructure, supporting both cooperative and non-cooperative interactions. Agents whose objectives are aligned, and where one agent can help another achieve greater reward by sacrificing some of its own reward, should choose a cooperative commitment to maximize their joint reward. We present a solution to the problem of how cooperative agents can efficiently find an (approximately) optimal commitment by querying about carefully-selected commitment choices. We prove structural properties of the agents’ values as functions of the parameters of the commitment specification, and develop a greedy method for composing a query with provable approximation bounds, which we empirically show can find nearly optimal commitments in a fraction of the time methods that lack our insights require.
 Enlarge
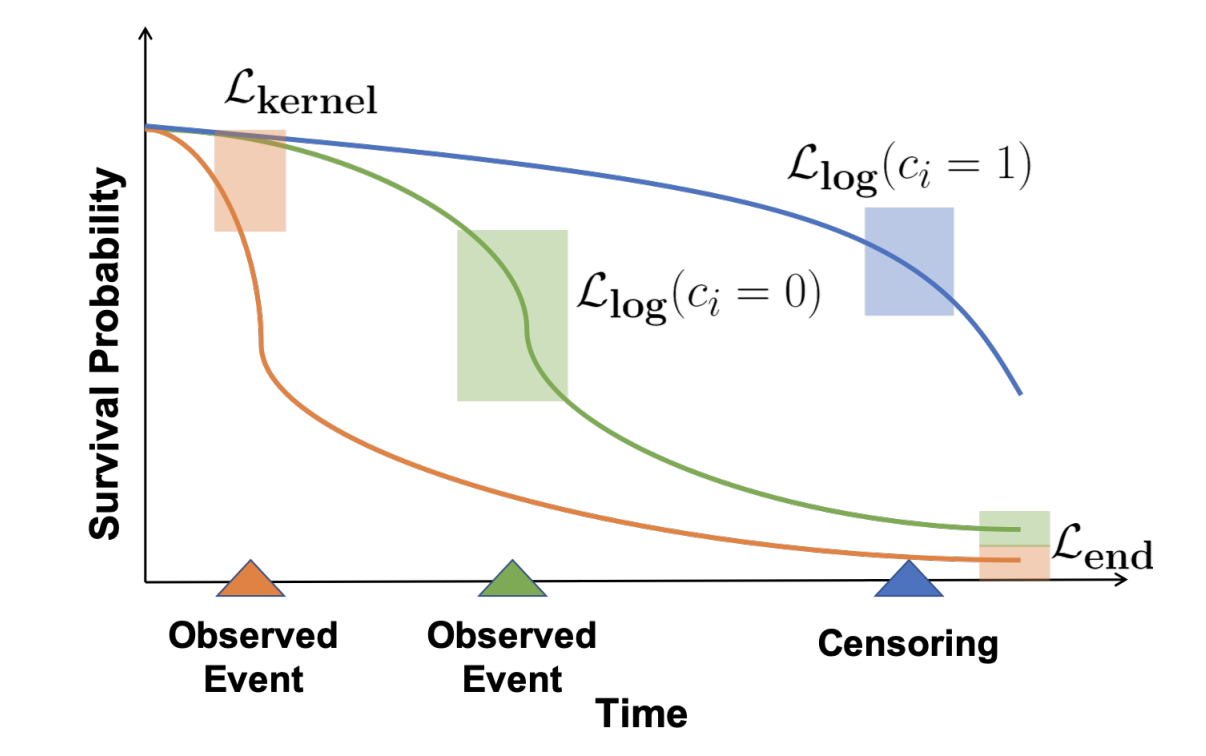
EnlargeEstimating Calibrated Individualized Survival Curves with Deep Learning
Fahad Kamran (University of Michigan), Jenna Wiens (University of Michigan)
In survival analysis, deep learning approaches have been proposed for estimating an individual’s probability of survival over some time horizon. Such approaches can capture complex non-linear relationships, without relying on restrictive assumptions regarding the relationship between an individual’s characteristics and their underlying survival process. To date, however, these methods have focused primarily on optimizing discriminative performance and have ignored model calibration. Well-calibrated survival curves present realistic and meaningful probabilistic estimates of the true underlying survival process for an individual. However, due to the lack of ground-truth regarding the underlying stochastic process of survival for an individual, optimizing and measuring calibration in survival analysis is an inherently difficult task. In this work, we i) highlight the shortcomings of existing approaches in terms of calibration and ii) propose a new training scheme for optimizing deep survival analysis models that maximizes discriminative performance, subject to good calibration. Compared to state-of-the-art approaches across two publicly available datasets, our proposed training scheme leads to significant improvements in calibration, while maintaining good discriminative performance.
 Enlarge
EnlargeEvolution Strategies for Approximate Solution of Bayesian Games
Zun Li (University of Michigan), Michael Wellman (University of Michigan)
We address the problem of solving complex Bayesian games, characterized by high-dimensional type and action spaces, many (> 2) players, and general-sum payoffs. Our approach applies to symmetric one-shot Bayesian games, with no given analytic structure. We represent agent strategies in parametric form as neural networks, and apply natural evolution strategies (NES) (Wierstra et al. 2014) for deep model optimization. For pure equilibrium computation, we formulate the problem as bi-level optimization, and employ NES in an iterative algorithm to implement both inner-loop best response optimization and outer-loop regret minimization. In simple games including first- and second-price auctions, it is capable of recovering known analytic solutions. For mixed equilibrium computation, we adopt an incremental strategy generation framework, with NES as strategy generator producing a finite sequence of approximate best-response strategies. We then calculate equilibria over this finite strategy set via a model-based optimization process. Both our pure and mixed equilibrium computation methods employ NES to efficiently search for strategies over the functional space, given only black-box simulation access to noisy payoff samples. We experimentally demonstrate the efficacy of all methods on two simultaneous sealed-bid auction games with distinct type distributions, and observe that the solutions exhibit qualitatively different behavior in these two environments.
 Enlarge
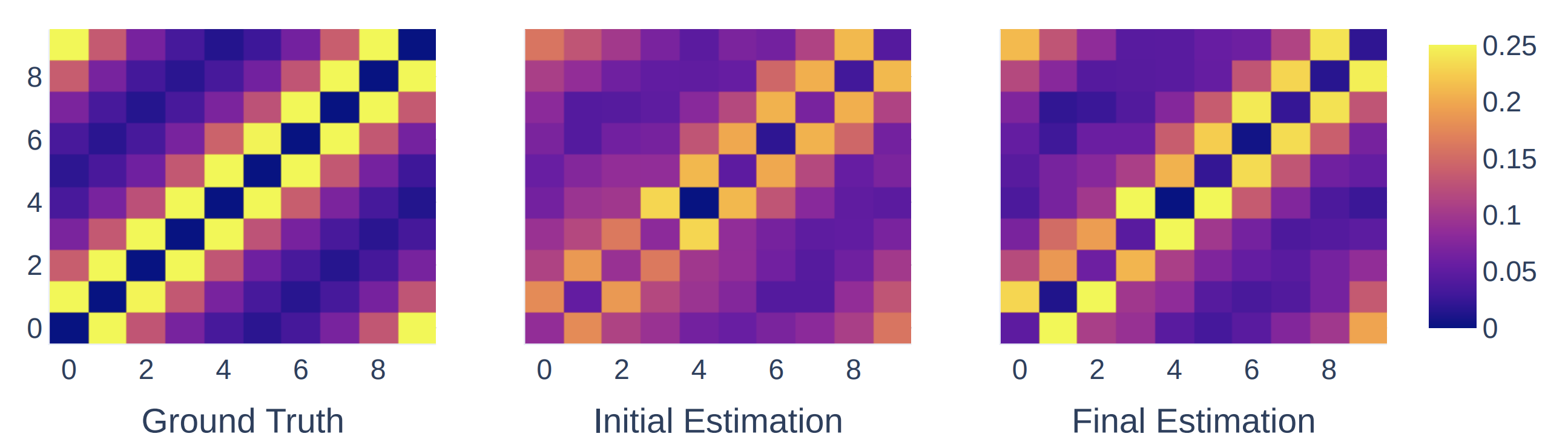
EnlargeGraph Neural Networks with Heterophily
Jiong Zhu (University of Michigan), Ryan A. Rossi (Adobe Research), Anup Rao (Adobe Research), Tung Mai (Adobe Research), Nedim Lipka (Adobe Research), Nesreen Ahmed (Intel Labs), Danai Koutra (University of Michigan)
Graph Neural Networks (GNNs) have proven to be useful for many different practical applications. However, many existing GNN models have implicitly assumed homophily among the nodes connected in the graph, and therefore have largely overlooked the important setting of heterophily, where most connected nodes are from different classes. In this work, we propose a novel framework called CPGNN that generalizes GNNs for graphs with either homophily or heterophily. The proposed framework incorporates an interpretable compatibility matrix for modeling the heterophily or homophily level in the graph, which can be learned in an end-to-end fashion, enabling it to go beyond the assumption of strong homophily. Theoretically, we show that replacing the compatibility matrix in our framework with the identity (which represents pure homophily) reduces to GCN. Our extensive experiments demonstrate the effectiveness of our approach in more realistic and challenging experimental settings with significantly less training data compared to previous works: CPGNN variants achieve state-of-the-art results in heterophily settings with or without contextual node features, while maintaining comparable performance in homophily settings.
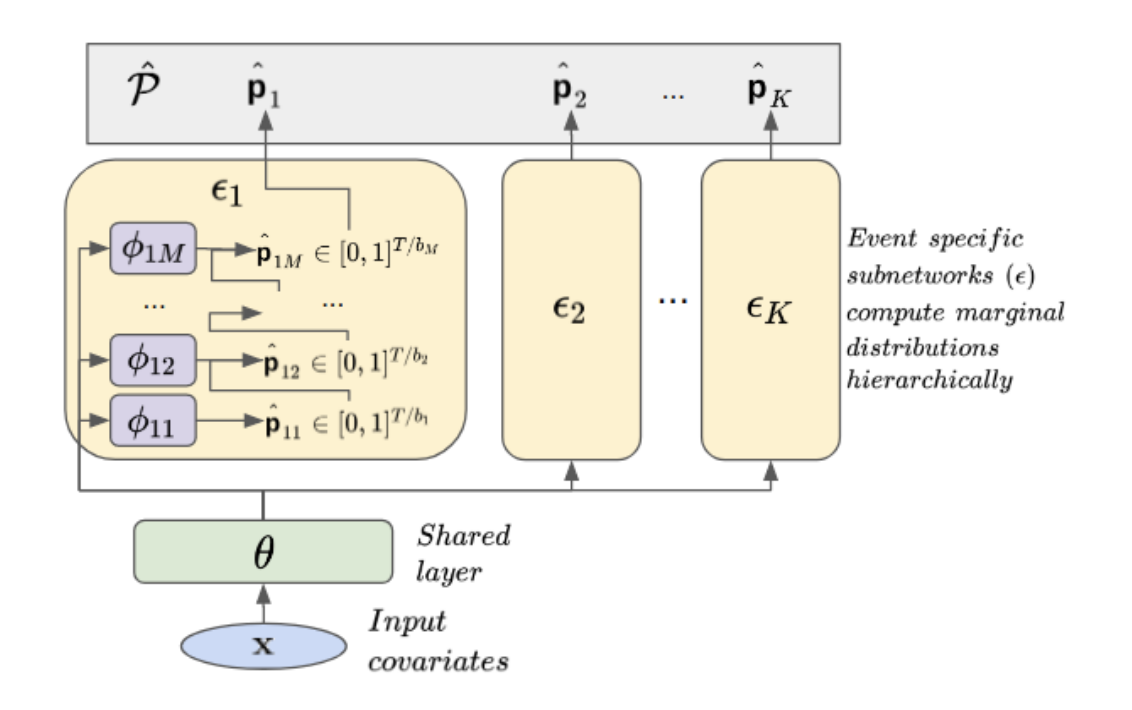 Enlarge
EnlargeA Hierarchical Approach to Multi-Event Survival Analysis
Donna E Tjandra (University of Michigan), Yifei He (University of Michigan), Jenna Wiens (University of Michigan)
In multi-event survival analysis, one aims to predict the probability of multiple different events occurring over some time horizon. One typically assumes that the timing of events is drawn from some distribution conditioned on an individual’s covariates. However, during training, one does not have access to this distribution, and the natural variation in the observed event times makes the task of survival prediction challenging, on top of the potential interdependence among events. To address this issue, we introduce a novel approach for multi-event survival analysis that models the probability of events hierarchically at different time scales, using coarse predictions (e.g., monthly predictions) to iteratively guide predictions at finer and finer grained time scales (e.g., daily predictions). We evaluate the proposed approach across several publicly available datasets in terms of both intra-event, inter-individual (global) and intra-individual, inter-event (local) consistency. We show that the proposed method consistently outperforms well-accepted and commonly used approaches to multi-event survival analysis. When estimating survival curves for Alzheimer’s disease and mortality, our approach achieves a C-index of 0.91 (95% CI 0.89-0.93) and a local consistency score of 0.97 (95% CI 0.94-0.98) compared to a C-index of 0.76 (95% CI 0.72-0.79) and a local consistency score of 0.89 (95% CI 0.82-0.94) when modeling each event separately. Overall, our approach improves the accuracy of survival predictions by iteratively reducing the original task to a set of nested, simpler subtasks.
 Enlarge
EnlargeHumor Knowledge Enriched Transformer for Understanding Multimodal Humor
Md Kamrul Hasan (University of Rochester), Sangwu Lee (University of Rochester), Wasifur Rahman (University of Rochester), Amir Zadeh (Carnegie Mellon University), Rada Mihalcea (University of Michigan), Louis-Philippe Morency (Carnegie Mellon University), Ehsan Hoque (University of Rochester)
Understanding humor requires understanding the verbal and non-verbal components as well as incorporating the appropriate context and external knowledge. In this paper, we propose Humor Knowledge Enriched Transformer (HKT) that can capture the gist of a multimodal humorous expression by integrating the preceding context and external knowledge. We incorporate humor-centric external knowledge into the model by capturing the ambiguity and sentiment present in the language. We encode all the textual, acoustic, visual, and external knowledge separately using Transformer based Encoders, followed by a cross attention layer to exchange information among them. Our model achieves 76.96% and 79.41% accuracy in humor/sarcasm punchline detection on UR-FUNNY and MUStaRD datasets – achieving a new state-of-the-art on both datasets with the margin of 6.35% and 7.81% respectively. Furthermore, we demonstrate that our model can capture interpretable, humor-inducing patterns from all modalities.
 Enlarge
EnlargeImproved Consistency Regularization for GANs
Zhengli Zhao (University of California, Irvine; Google Research), Sameer Singh (University of California, Irvine), Honglak Lee (Google Research), Zizhao Zhang (Google Research), Augustus Odena (Google Research), Han Zhang (Google Research)
Recent work (Zhang et al. 2020) has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN (Brock, Donahue, and Simonyan 2019) model and improve the FID from 6.66 to 5.38, which is the best score at that model size.