 MENU
MENU 

Seventeen papers by CSE researchers at NeurIPS 2024

A total of 17 papers by researchers affiliated with CSE are being presented at the 2024 Conference on Neural Information Processing Systems (NeurIPS), a leading international conference in the area of machine learning and artificial intelligence (AI). The 2024 conference is taking place December 10-15 in Vancouver, Canada.
New research being presented at the conference by CSE authors spans a range of topics, including machine learning biases, neural network efficiency, visual question answering, and more.
The papers being presented are as follows, with the names of authors affiliated with CSE in bold:
Multi-Object Hallucination in Vision Language Models
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David Fouhey, Joyce Chai
Abstract: Large vision language models (LVLMs) often suffer from object hallucination, producing objects not present in the given images. While current benchmarks for object hallucination primarily concentrate on the presence of a single object class rather than individual entities, this work systematically investigates multi-object hallucination, examining how models misperceive (e.g., invent nonexistent objects or become distracted) when tasked with focusing on multiple objects simultaneously. We introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol that considers the distribution of object classes within a single image during testing and uses visual referring prompts to eliminate ambiguity. With comprehensive empirical studies and analysis of potential factors leading to multi-object hallucination, we found that (1). LVLMs suffer more hallucinations when focusing on multiple objects compared to a single object. (2). The tested object class distribution affects hallucination behaviors, indicating that LVLMs may follow shortcuts and spurious correlations. (3). Hallucinatory behaviors are influenced by data-specific factors, salience and frequency, and model intrinsic behaviors. We hope to enable LVLMs to recognize and reason about multiple objects that often occur in realistic visual scenes, provide insights, and quantify our progress towards mitigating the issues.

Distributed Least Squares in Small Space via Sketching and Bias Reduction
Sachin Garg, Kevin Tan, Michał Dereziński
Abstract: Matrix sketching is a powerful tool for reducing the size of large data matrices. Yet there are fundamental limitations to this size reduction when we want to recover an accurate estimator for a task such as least square regression. We show that these limitations can be circumvented in the distributed setting by designing sketching methods that minimize the bias of the estimator, rather than its error. In particular, we give a sparse sketching method running in optimal space and current matrix multiplication time, which recovers a nearly-unbiased least squares estimator using two passes over the data. This leads to new communication-efficient distributed averaging algorithms for least squares and related tasks, which directly improve on several prior approaches. Our key novelty is a new bias analysis for sketched least squares, giving a sharp characterization of its dependence on the sketch sparsity. The techniques include new higher-moment restricted Bai-Silverstein inequalities, which are of independent interest to the non-asymptotic analysis of deterministic equivalents for random matrices that arise from sketching.
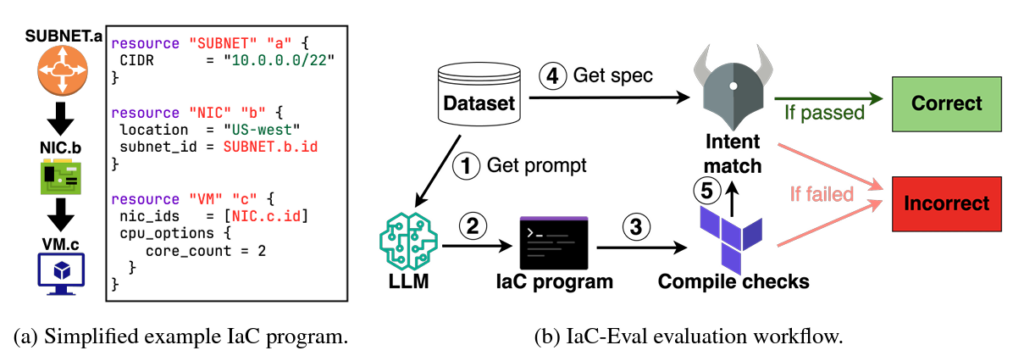
IaC-Eval: A code generation benchmark for Infrastructure-as-Code programs
Patrick Tser Jern Kon, Jiachen Liu, Yiming Qiu, Weijun Fan, Ting He, Lei Lin, Haoran Zhang, Owen Park, George Elengikal, Yuxin Kang, Ang Chen, Mosharaf Chowdhury, Myungjin Lee, Xinyu Wang
Abstract: Infrastructure-as-Code (IaC), an important component of cloud computing, allows the definition of cloud infrastructure in high-level programs. However, developing IaC programs is challenging, complicated by factors that include the burgeoning complexity of the cloud ecosystem (e.g., diversity of cloud services and workloads), and the relative scarcity of IaC-specific code examples and public repositories. While large language models (LLMs) have shown promise in general code generation and could potentially aid in IaC development, no benchmarks currently exist for evaluating their ability to generate IaC code. We present IaC-Eval, a first step in this research direction. IaC-Eval’s dataset includes 458 human-curated scenarios covering a wide range of popular AWS services, at varying difficulty levels. Each scenario mainly comprises a natural language IaC problem description and an infrastructure intent specification. The former is fed as user input to the LLM, while the latter is a general notion used to verify if the generated IaC program conforms to the user’s intent; by making explicit the problem’s requirements that can encompass various cloud services, resources and internal infrastructure details. Our in-depth evaluation shows that contemporary LLMs perform poorly on IaC-Eval, with the top-performing model, GPT-4, obtaining a pass@1 accuracy of 19.36%. In contrast, it scores 86.6% on EvalPlus, a popular Python code generation benchmark, highlighting a need for advancements in this domain. We open-source the IaC-Eval dataset and evaluation framework at https://github.com/autoiac-project/iac-eval to enable future research on LLM-based IaC code generation.
On the Impact of Feature Heterophily on Link Prediction with Graph Neural Networks
Jiong Zhu, Gaotang Li, Yao-An Yang, Jing Zhu, Xuehao Cui, Danai Koutra
Abstract: Heterophily, or the tendency of connected nodes in networks to have different class labels or dissimilar features, has been identified as challenging for many Graph Neural Network (GNN) models. While the challenges of applying GNNs for node classification when class labels display strong heterophily are well understood, it is unclear how heterophily affects GNN performance in other important graph learning tasks where class labels are not available. In this work, we focus on the link prediction task and systematically analyze the impact of heterophily in node features on GNN performance. Theoretically, we first introduce formal definitions of homophilic and heterophilic link prediction tasks, and present a theoretical framework that highlights the different optimizations needed for the respective tasks. We then analyze how different link prediction encoders and decoders adapt to varying levels of feature homophily and introduce designs for improved performance. Our empirical analysis on a variety of synthetic and real-world datasets confirms our theoretical insights and highlights the importance of adopting learnable decoders and GNN encoders with ego- and neighbor-embedding separation in message passing for link prediction tasks beyond homophily.
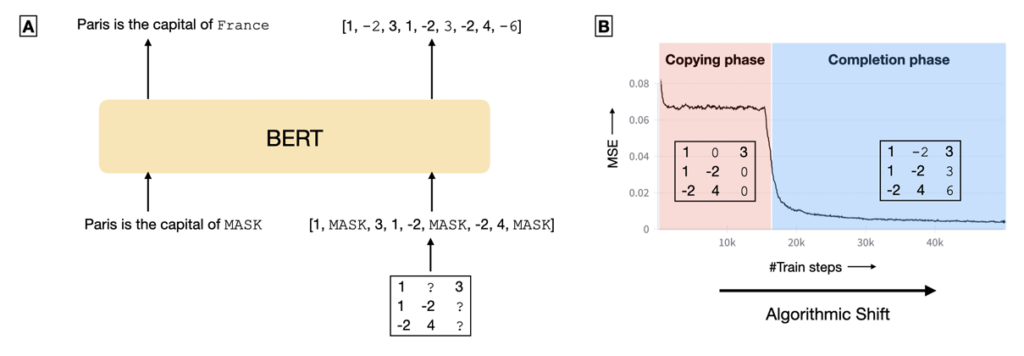
Abrupt Learning in Transformers: A Case Study on Matrix Completion
Pulkit Gopalani, Ekdeep S Lubana, Wei Hu
Abstract: Recent analysis on the training dynamics of Transformers has unveiled an interesting characteristic: the training loss plateaus for a significant number of training steps, and then suddenly (and sharply) drops to near–optimal values. To understand this phenomenon in depth, we formulate the low-rank matrix completion problem as a masked language modeling (MLM) task, and show that it is possible to train a BERT model to solve this task to low error. Furthermore, the loss curve shows a plateau early in training followed by a sudden drop to near-optimal values, despite no changes in the training procedure or hyper-parameters. To gain interpretability insights into this sudden drop, we examine the model’s predictions, attention heads, and hidden states before and after this transition. Concretely, we observe that (a) the model transitions from simply copying the masked input to accurately predicting the masked entries; (b) the attention heads transition to interpretable patterns relevant to the task; and (c) the embeddings and hidden states encode information relevant to the problem. We also analyze the training dynamics of individual model components to understand the sudden drop in loss.
Who’s Gaming the System? A Causally-Motivated Approach for Detecting Strategic Adaptation
Trenton Chang, Lindsay Warrenburg, Sae-Hwan Park, Ravi Parikh, Maggie Makar, Jenna Wiens
Abstract: In many settings, machine learning models may be used to inform decisions that impact individuals or entities who interact with the model. Such entities, or agents, may game model decisions by manipulating their inputs to the model to obtain better outcomes and maximize some utility. We consider a multi-agent setting where the goal is to identify the “worst offenders”: agents that are gaming most aggressively. However, identifying such agents is difficult without knowledge of their utility function. Thus, we introduce a framework in which each agent’s tendency to game is parameterized via a scalar. We show that this gaming parameter is only partially identifiable. By recasting the problem as a causal effect estimation problem where different agents represent different “treatments,” we prove that a ranking of all agents by their gaming parameters is identifiable. We present empirical results in a synthetic data study validating the usage of causal effect estimation for gaming detection and show in a case study of diagnosis coding behavior in the U.S. that our approach highlights features associated with gaming.
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Zhuoqing Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
Abstract: Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.

AutoGuide: Automated Generation and Selection of Context-Aware Guidelines for Large Language Model Agents
Yao Fu, Dong-Ki Kim, Jaekyeom Kim, Sungryull Sohn, Lajanugen Logeswaran, Kyunghoon Bae, Honglak Lee
Abstract: Recent advances in large language models (LLMs) have empowered AI agents capable of performing various sequential decision-making tasks. However, effectively guiding LLMs to perform well in unfamiliar domains like web navigation, where they lack sufficient knowledge, has proven to be difficult with the demonstration-based in-context learning paradigm. In this paper, we introduce a novel framework, called AutoGuide, which addresses this limitation by automatically generating context-aware guidelines from offline experiences. Importantly, each context-aware guideline is expressed in concise natural language and follows a conditional structure, clearly describing the context where it is applicable. As a result, our guidelines facilitate the provision of relevant knowledge for the agent’s current decision-making process, overcoming the limitations of the conventional demonstration-based learning paradigm. Our evaluation demonstrates that AutoGuide significantly outperforms competitive baselines in complex benchmark domains, including real-world web navigation.
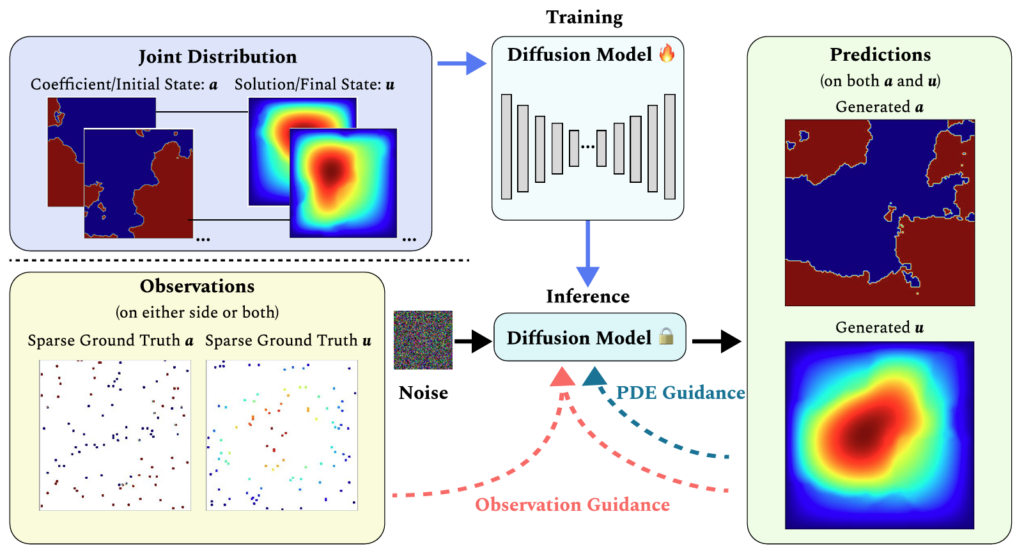
DiffusionPDE: Generative PDE-Solving under Partial Observation
Jiahe Huang, Guandao Yang, Zichen Wang, Jeong Joon Park
Abstract: We introduce a general framework for solving partial differential equations (PDEs) using generative diffusion models. In particular, we focus on the scenarios where we do not have the full knowledge of the scene necessary to apply classical solvers. Most existing forward or inverse PDE approaches perform poorly when the observations on the data or the underlying coefficients are incomplete, which is a common assumption for real-world measurements. In this work, we propose DiffusionPDE that can simultaneously fill in the missing information and solve a PDE by modeling the joint distribution of the solution and coefficient spaces. We show that the learned generative priors lead to a versatile framework for accurately solving a wide range of PDEs under partial observation, significantly outperforming the state-of-the-art methods for both forward and inverse directions.
Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of LLM Agents
Giorgio Piatti, Zhijing Jin, Max Kleiman-Weiner, Bernhard Schölkopf, Mrinmaya Sachan, Rada Mihalcea
Abstract: As AI systems pervade human life, ensuring that large language models (LLMs) make safe decisions remains a significant challenge. We introduce the Governance of the Commons Simulation (GovSim), a generative simulation platform designed to study strategic interactions and cooperative decision-making in LLMs. In GovSim, a society of AI agents must collectively balance exploiting a common resource with sustaining it for future use. This environment enables the study of how ethical considerations, strategic planning, and negotiation skills impact cooperative outcomes. We develop an LLM-based agent architecture and test it with the leading open and closed LLMs. We find that all but the most powerful LLM agents fail to achieve a sustainable equilibrium in GovSim, with the highest survival rate below 54%. Ablations reveal that successful multi-agent communication between agents is critical for achieving cooperation in these cases. Furthermore, our analyses show that the failure to achieve sustainable cooperation in most LLMs stems from their inability to formulate and analyze hypotheses about the long-term effects of their actions on the equilibrium of the group. Finally, we show that agents that leverage “Universalization”-based reasoning, a theory of moral thinking, are able to achieve significantly better sustainability. Taken together, GovSim enables us to study the mechanisms that underlie sustainable self-government with specificity and scale. We open source the full suite of our research results, including the simulation environment, agent prompts, and a comprehensive web interface.
Stochastic Newton Proximal Extragradient Method
Ruichen Jiang, Michał Dereziński, Aryan Mokhtari
Abstract: Stochastic second-order methods achieve fast local convergence in strongly convex optimization by using noisy Hessian estimates to precondition the gradient. However, these methods typically reach superlinear convergence only when the stochastic Hessian noise diminishes, increasing per-iteration costs over time. Recent work in [1] addressed this with a Hessian averaging scheme that achieves superlinear convergence without higher per-iteration costs. Nonetheless, the method has slow global convergence, requiring up to Õ(κ2) iterations to reach the superlinear rate of Õ((1/t)t/2), where κ is the problem’s condition number. In this paper, we propose a novel stochastic Newton proximal extragradient method that improves these bounds, achieving a faster global linear rate and reaching the same fast superlinear rate in Õ(κ) iterations. We accomplish this by extending the Hybrid Proximal Extragradient (HPE) framework, achieving fast global and local convergence rates for strongly convex functions with access to a noisy Hessian oracle.
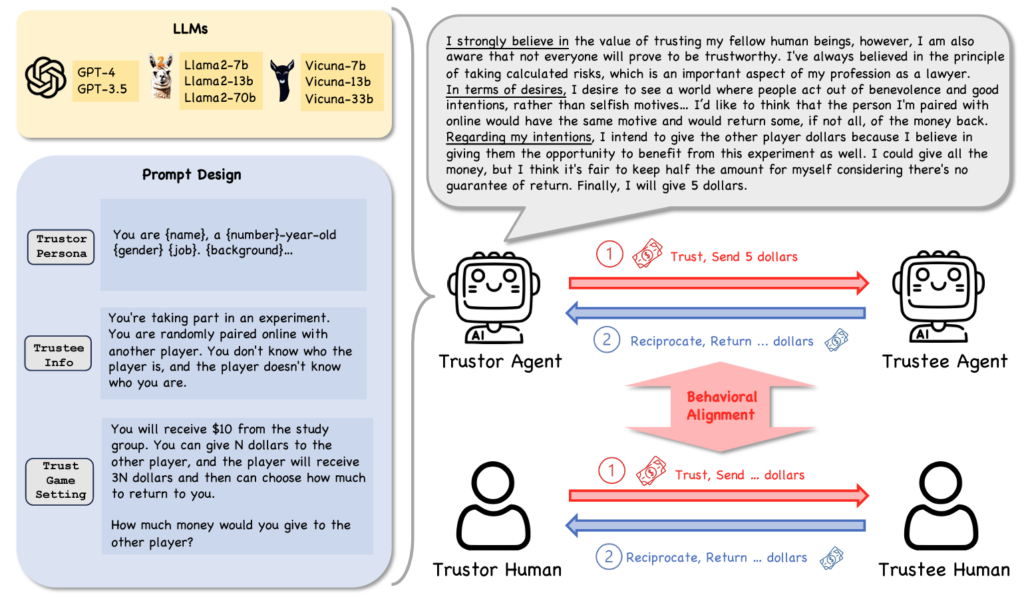
Can Large Language Model Agents Simulate Human Trust Behavior?
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, James Evans, Philip Torr, Bernard Ghanem, Guohao Li
Abstract: Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in social science and role-playing applications. However, one fundamental question remains: can LLM agents really simulate human behavior? In this paper, we focus on one critical and elemental behavior in human interactions, trust, and investigate whether LLM agents can simulate human trust behavior. We first find that LLM agents generally exhibit trust behavior, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that GPT-4 agents manifest high behavioral alignment with humans in terms of trust behavior, indicating the feasibility of simulating human trust behavior with LLM agents. In addition, we probe the biases of agent trust and differences in agent trust towards other LLM agents and humans. We also explore the intrinsic properties of agent trust under conditions including external manipulations and advanced reasoning strategies. Our study provides new insights into the behaviors of LLM agents and the fundamental analogy between LLMs and humans beyond value alignment. We further illustrate broader implications of our discoveries for applications where trust is paramount.
Learning-Augmented Approximation Algorithms for Maximum Cut and Related Problems
Vincent Cohen-Addad, Tommaso d’Orsi, Anupam Gupta, Euiwoong Lee, Debmalya Panigrahi
Abstract: In recent years, there has been a surge of interest in the use of machine-learned predictions to bypass worst-case lower bounds for classical problems in combinatorial optimization. So far, the focus has mostly been on online algorithms, where information-theoretic barriers are overcome using predictions about the unknown future. In this paper, we consider the complementary question of using learned information to overcome computational barriers in the form of approximation hardness of polynomial-time algorithms for NP-hard (offline) problems. We show that noisy predictions about the optimal solution can be used to break classical hardness results for maximization problems such as the max-cut problem and more generally, maximization versions of constraint satisfaction problems (CSPs).
Clustering with Non-adaptive Subset Queries
Hadley Black, Euiwoong Lee, Arya Mazumdar, Barna Saha
Abstract: Recovering the underlying clustering of a set U of n points by asking pair-wise same-cluster queries has garnered significant interest in the last decade. Given a query S⊂U, |S|=2, the oracle returns yes if the points are in the same cluster and no otherwise. For adaptive algorithms with pair-wise queries, the number of required queries is known to be Θ(nk), where k is the number of clusters. However, non-adaptive schemes require Ω(n2) queries, which matches the trivial O(n2) upper bound attained by querying every pair of points. To break the quadratic barrier for non-adaptive queries, we study a generalization of this problem to subset queries for |S|>2, where the oracle returns the number of clusters intersecting S. Allowing for subset queries of unbounded size, O(n) queries is possible with an adaptive scheme (Chakrabarty-Liao, 2024). However, the realm of non-adaptive algorithms is completely unknown.
In this paper, we give the first non-adaptive algorithms for clustering with subset queries. Our main result is a non-adaptive algorithm making O(nlogk⋅(logk+loglogn)2) queries, which improves to O(nloglogn) when k is a constant. We also consider algorithms with a restricted query size of at most s. In this setting we prove that Ω(max(n2/s2,n)) queries are necessary and obtain algorithms making Õ (n2k/s2) queries for any s≤n‾√ and Õ (n2/s) queries for any s≤n. We also consider the natural special case when the clusters are balanced, obtaining non-adaptive algorithms which make O(nlogk)+Õ (k) and O(nlog2k) queries. Finally, allowing two rounds of adaptivity, we give an algorithm making O(nlogk) queries in the general case and O(nloglogk) queries when the clusters are balanced.
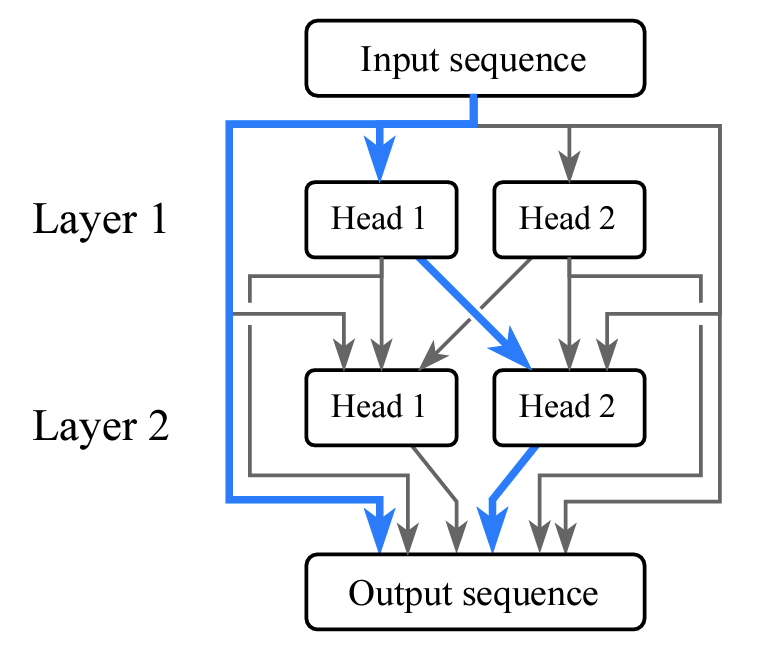
Hypothesis Testing the Circuit Hypothesis in LLMs
Claudia Shi, Nicolas Beltran Velez, Achille Nazaret, Carolina Zheng, Adrià Garriga-Alonso, Andrew Jesson, Maggie Makar, David Blei
Abstract: Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented. One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis? In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them. The criteria focus on the extent to which the LLM’s behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal. We apply these tests to six circuits described in the research literature. We find that synthetic circuits– circuits that are hard-coded in the model– align with the idealized properties. Circuits discovered in Transformer models satisfy the criteria to varying degrees. To facilitate future empirical studies of circuits, we created the circuitry package, a wrapper around the TransformerLens library, which abstracts away lower-level manipulations of hooks and activations. The software is available at github.com/blei-lab/circuitry.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
David Romero, Chenyang Lyu, Haryo Akbarianto Wibowo, Teresa Lynn, Injy Hamed, Aditya Nanda Kishore, Aishik Mandal, Alina Dragonetti, Artem Abzaliev, Atnafu Lambebo Tonja, Bontu Fufa Balcha, Chenxi Whitehouse, Christian Salamea, Dan John Velasco, David Ifeoluwa Adelani, David Le Meur, Emilio Villa-Cueva, Fajri Koto , Fauzan Farooqui , Frederico Belcavello, Ganzorig Batnasan, Gisela Vallejo, Grainne Caulfield, Guido Ivetta, Haiyue Song, Henok Biadglign Ademtew, Hernán Maina, Holy Lovenia, Israel Abebe Azime, Jan Christian Blaise Cruz, Jay Gala, Jiahui Geng, Jesus-German Ortiz-Barajas, Jinheon Baek, Jocelyn Dunstan, Laura Alonso Alemany, Kumaranage Ravindu Yasas Nagasinghe, Luciana Benotti, Luis Fernando D’Haro, Marcelo Viridiano, Marcos Estecha-Garitagoitia, Maria Camila Buitrago Cabrera, Mario Rodríguez-Cantelar, Mélanie Jouitteau, Mihail Mihaylov, Naome Etori, Mohamed Fazli Mohamed Imam, Muhammad Farid Adilazuarda, Munkhjargal Gochoo, Munkh-Erdene Otgonbold, Olivier Niyomugisha, Paula Mónica Silva, Pranjal Chitale, Raj Dabre, Rendi Chevi, Ruochen Zhang, Ryandito Diandaru, Samuel Cahyawijaya, Santiago Góngora, Soyeong Jeong, Sukannya Purkayastha, Tatsuki Kuribayashi, Teresa Clifford, Thanmay Jayakumar, Tiago Timponi Torrent, Toqeer Ehsan, Vladimir Araujo, Yova Kementchedjhieva, Zara Burzo, Zheng Wei Lim, Zheng Xin Yong, Oana Ignat, Joan Nwatu, Rada Mihalcea, Thamar Solorio, Alham Fikri Aji
Abstract: Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 30 countries on four continents, covering 31 languages with 13 scripts, providing a total of 10k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.

Images that Sound: Composing Images and Sounds on a Single Canvas
Ziyang Chen, Daniel Geng, Andrew Owens
Abstract: Spectrograms are 2D representations of sound that look very different from the images found in our visual world. And natural images, when played as spectrograms, make unnatural sounds. In this paper, we show that it is possible to synthesize spectrograms that simultaneously look like natural images and sound like natural audio. We call these visual spectrograms images that sound. Our approach is simple and zero-shot, and it leverages pre-trained text-to-image and text-to-spectrogram diffusion models that operate in a shared latent space. During the reverse process, we denoise noisy latents with both the audio and image diffusion models in parallel, resulting in a sample that is likely under both models. Through quantitative evaluations and perceptual studies, we find that our method successfully generates spectrograms that align with a desired audio prompt while also taking the visual appearance of a desired image prompt. Please see our project page for video results.