 MENU
MENU 

Eleven papers by CSE researchers at VLDB 2024
Eleven papers by researchers affiliated with CSE are being presented at the 2024 International Conference on Very Large Databases (VLDB). Taking place August 26-30 in Guangzhou, China, VLDB is a top international forum for new research and developments in areas across data management, database architecture, data mining, data privacy and security, and more.
With 11 papers out of around 250 total, CSE authors are behind nearly 5% of all new research appearing at the conference. Their research spans the data science field, bringing innovative new knowledge to topics including exploratory data analysis, relational table embedding, graph sparsification, temporal motif mining, and others.
The following papers are appearing at the conference, with the names of CSE researchers in bold:
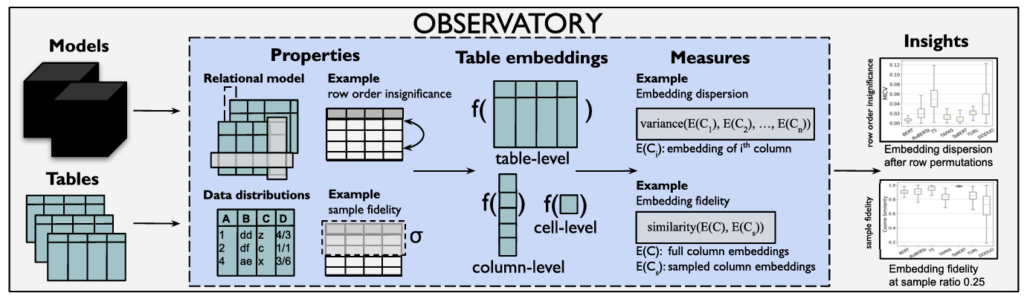
“Observatory: Characterizing Embeddings of Relational Tables”
Tianji Cong, Madelon Hulsebos, Zhenjie Sun, Paul Groth, H. V. Jagadish
Abstract: Language models and specialized table embedding models have recently demonstrated strong performance on many tasks over tabular data. Researchers and practitioners are keen to leverage these models in many new application contexts; but limited understanding of the strengths and weaknesses of these models, and the table representations they generate, makes the process of finding a suitable model for a given task reliant on trial and error. There is an urgent need to gain a comprehensive understanding of these models to minimize inefficiency and failures in downstream usage.
To address this need, we propose Observatory, a formal framework to systematically analyze embedding representations of relational tables. Motivated both by invariants of the relational data model and by statistical considerations regarding data distributions, we define eight primitive properties, and corresponding measures to quantitatively characterize table embeddings for these properties. Based on these properties, we define an extensible framework to evaluate language and table embedding models. We collect and synthesize a suite of datasets and use Observatory to analyze nine such models. Our analysis provides insights into the strengths and weaknesses of learned representations over tables. We find, for example, that some models are sensitive to table structure such as column order, that functional dependencies are rarely reflected in embeddings, and that specialized table embedding models have relatively lower sample fidelity. Such insights help researchers and practitioners better anticipate model behaviors and select appropriate models for their downstream tasks, while guiding researchers in the development of new models.
“Query Refinement for Diversity Constraint Satisfaction”
Jinyang Li, Yuval Moskovitch, Julia Stoyanovich, H. V. Jagadish
Abstract: Diversity, group representation, and similar needs often apply to query results, which in turn require constraints on the sizes of various subgroups in the result set. Traditional relational queries only specify conditions as part of the query predicate(s), and do not support such restrictions on the output. In this paper, we study the problem of modifying queries to have the result satisfy constraints on the sizes of multiple subgroups in it. This problem, in the worst case, cannot be solved in polynomial time. Yet, with the help of provenance annotation, we are able to develop a query refinement method that works quite efficiently, as we demonstrate through extensive experiments.
“Data-Driven Insight Synthesis for Multi-Dimensional Data”
Junjie Xing, Xinyu Wang, H. V. Jagadish
Abstract: Exploratory data analysis can uncover interesting data insights from data. Current methods utilize “interestingness measures” designed based on system designers’ perspectives, thus inherently restricting the insights to their defined scope. These systems, consequently, may not adequately represent a broader range of user interests. Furthermore, most existing approaches that formulate “interestingness measure” are rule-based, which makes them inevitably brittle and often requires holistic re-design when new user needs are discovered.
This paper presents a data-driven technique for deriving an “interestingness measure” that learns from annotated data. We further develop an innovative annotation algorithm that significantly reduces the annotation cost, and an insight synthesis algorithm based on the Markov Chain Monte Carlo method for efficient discovery of interesting insights. We consolidate these ideas into a system. Our experimental outcomes and user studies demonstrate that DAISY can effectively discover a broad range of interesting insights, thereby substantially advancing the current state-of-the-art.

“Demystifying Graph Sparsification Algorithms in Graph Properties Preservation”
Yuhan Chen, Haojie Ye, Sanketh Vedula, Alex Bronstein, Ronald Dreslinski, Trevor Mudge, Nishil Talati
Abstract: Graph sparsification is a technique that approximates a given graph by a sparse graph with a subset of vertices and/or edges. The goal of an effective sparsification algorithm is to maintain specific graph properties relevant to the downstream task while minimizing the graph’s size. Graph algorithms often suffer from long execution time due to the irregularity and the large real-world graph size. Graph sparsification can be applied to greatly reduce the run time of graph algorithms by substituting the full graph with a much smaller sparsified graph, without significantly degrading the output quality. However, the interaction between numerous sparsifiers and graph properties is not widely explored, and the potential of graph sparsification is not fully understood.
In this work, we cover 16 widely-used graph metrics, 12 representative graph sparsification algorithms, and 14 real-world input graphs spanning various categories, exhibiting diverse characteristics, sizes, and densities. We developed a framework to extensively assess the performance of these sparsification algorithms against graph metrics, and provide insights to the results. Our study shows that there is no one sparsifier that performs the best in preserving all graph properties, e.g. sparsifiers that preserve distance-related graph properties (eccentricity) struggle to perform well on Graph Neural Networks (GNN). This paper presents a comprehensive experimental study evaluating the performance of sparsification algorithms in preserving essential graph metrics. The insights inform future research in incorporating matching graph sparsification to graph algorithms to maximize benefits while minimizing quality degradation. Furthermore, we provide a framework to facilitate the future evaluation of evolving sparsification algorithms, graph metrics, and ever-growing graph data.
“Everest: GPU-Accelerated System For Mining Temporal Motifs”
Yichao Yuan, Haojie Ye, Sanketh Vedula, Wynn M Kaza, Nishil Talati
Abstract: Temporal motif mining is the task of finding the occurrences of subgraph patterns within a large input temporal graph that obey the specified structural and temporal constraints. Despite its utility in several critical application domains that demand high performance (e.g., detecting fraud in financial transaction graphs), the performance of existing software is limited on commercial hardware platforms, in that it runs for tens of hours. This paper presents Everest—a system that efficiently maps the workload of mining (supports both enumeration and counting) temporal motifs to the highly parallel GPU architecture. In particular, using an input temporal graph and a more expressive user-defined temporal motif query definition compared to prior works, Everest generates an execution plan and runtime primitives that optimize the workload execution by exploiting the high compute throughput of a GPU. Everest generates motif-specific mining code to reduce long-latency memory accesses and frequent thread divergence operations. Everest incorporates novel low-cost runtime mechanisms to enable load balancing to improve GPU hardware utilization. To support large graphs that do not fit on GPU memory, Everest also supports multi-GPU execution by intelligently partitioning the edge list that prevents inter-GPU communication. Everest hides the implementation complexity of presented optimizations away from the targeted system user for better usability. Our evaluation shows that, using proposed optimizations, Everest improves the performance of a baseline GPU implementation by 19X, on average.

“Optimizing Video Selection LIMIT Queries With Commonsense Knowledge”
Wenjia He, Ibrahim Sabek, Yuze Lou, Michael Cafarella
Abstract: Video is becoming a major part of contemporary data collection. It is increasingly important to process video selection queries — selecting videos that contain target objects. Advances in neural networks allow us to detect the objects in an image, and thereby offer query systems to examine the content of the video. Unfortunately, neural network-based approaches have long inference times. Processing this type of query through a standard scan would be time-consuming and would involve applying complex detectors to numerous irrelevant videos. It is tempting to try to improve query times by computing an index in advance. But unfortunately, many frames will never be beneficial for any query. Time spent processing them, whether at index time or at query time, is simply wasted computation.
We propose a novel index mechanism to optimize video selection queries with commonsense knowledge. Commonsense knowledge consists of fundamental information about the world, such as the fact that a tennis racket is a tool designed for hitting a tennis ball. To save computation, an inexpensive but lossy index can be intentionally created, but this may result in missed target objects and suboptimal query time performance. Our mechanism addresses this issue by constructing probabilistic models from commonsense knowledge to patch the lossy index and then prioritizing predicate-related videos at query time. This method can achieve significant performance improvements comparable to those of a full index while keeping the construction costs of a lossy index. We describe our prototype system, Paine, plus experiments on two video corpora. We show our best optimization method can process up to 97.79% fewer videos compared to baselines. Even the model constructed without any video content can yield a 75.39% improvement over baselines.
“CohortNet: Empowering Cohort Discovery for Interpretable Healthcare Analytics”
Qingpeng Cai, Kaiping Zheng, H. V. Jagadish, Beng Chin Ooi, James WL Yip
Abstract: Cohort studies are of significant importance in the field of healthcare analytics. However, existing methods typically involve manual, labor-intensive, and expert-driven pattern definitions or rely on simplistic clustering techniques that lack medical relevance. Automating cohort studies with interpretable patterns has great potential to facilitate healthcare analytics and data management but remains an unmet need in prior research efforts. In this paper, we present a cohort auto-discovery framework for interpretable healthcare analytics. It focuses on the effective identification, representation, and exploitation of cohorts characterized by medically meaningful patterns. In the framework, we propose CohortNet, a core model that can learn fine-grained patient representations by separately processing each feature, considering both individual feature trends and feature interactions at each time step. Subsequently, it employs K-Means in an adaptive manner to classify each feature into distinct states and a heuristic cohort exploration strategy to effectively discover substantial cohorts with concrete patterns. For each identified cohort, it learns comprehensive cohort representations with credible evidence through associated patient retrieval. Ultimately, given a new patient, CohortNet can leverage relevant cohorts with distinguished importance which can provide a more holistic understanding of the patient’s conditions. Extensive experiments on three real-world datasets demonstrate that it consistently outperforms state-of-the-art approaches, resulting in improvements in AUC-PR scores ranging from 2.8% to 4.1%, and offers interpretable insights from diverse perspectives in a top-down fashion.
“Chameleon: Foundation Models for Fairness-aware Multi-modal Data Augmentation to Enhance Coverage of Minorities”
Mahdi Erfanian, H. V. Jagadish, Abolfazl Asudeh
Abstract: The potential harms of the under-representation of minorities in training data, particularly in multi-modal settings, is a well-recognized concern. While there has been extensive effort in detecting such under-representation, resolution has remained a challenge. With recent advancements in generative AI, large language models and foundation models have emerged as versatile tools across various domains. In this paper, we propose Chameleon, a system that efficiently utilizes these tools to augment a data set with a minimal addition of synthetically generated tuples, in order to enhance the coverage of the under-represented groups. Our system follows a rejection sampling approach to ensure the generated tuples have a high quality and follow the underlying distribution. In order to minimize the rejection chance of the generated tuples, we propose multiple strategies for providing a guide for the foundation model. Our experiment results, in addition to confirming the efficiency of our proposed algorithms, illustrate the effectiveness of our approach, as the unfairness of the model in a downstream task significantly dropped after data repair using Chameleon.
“Hit the Gym: Accelerating Query Execution to Efficiently Bootstrap Behavior Models for Self-Driving Database Management Systems”
Wan Shen Lim, Lin Ma, William Zhang, Matthew Butrovich, Samuel I Arch, Andrew Pavlo
Abstract: Autonomous database management systems (DBMSs) aim to optimize themselves automatically without human guidance. They rely on machine learning (ML) models that predict their run-time behavior to evaluate whether a candidate configuration is beneficial without the expensive execution of queries. However, the high cost of collecting the training data to build these models makes them impractical for real-world deployments. Furthermore, these models are instance-specific and thus require retraining whenever the DBMS’s environment changes. State-of-the-art methods spend over 93% of their time running queries for training versus tuning.
To mitigate this problem, we present the Boot framework for automatically accelerating training data collection in DBMSs. Boot utilizes macro- and micro-acceleration (MMA) techniques that modify query execution semantics with approximate run-time telemetry and skip repetitive parts of the training process. To evaluate Boot, we integrated it into a database gym for PostgreSQL. Our experimental evaluation shows that Boot reduces training collection times by up to 268x with modest degradation in model accuracy. These results also indicate that our MMA-based approach scales with dataset size and workload complexity.
“ElasticNotebook: Enabling Live Migration for Computational Notebooks”
Zhaoheng Li, Pranav Gor, Rahul Prabhu, Hui Yu, Yuzhou Mao, Yongjoo Park
Abstract: Computational notebooks (e.g., Jupyter, Google Colab) are widely used for interactive data science and machine learning. In those frameworks, users can start a session, then execute cells (i.e., a set of statements) to create variables, train models, visualize results, etc. Unfortunately, existing notebook systems do not offer live migration: when a notebook launches on a new machine, it loses its state, preventing users from continuing their tasks from where they had left off. This is because, unlike DBMS, the sessions directly rely on underlying kernels (e.g., Python/R interpreters) without an additional data management layer. Existing techniques for preserving states, such as copying all variables or OS-level checkpointing, are unreliable (often fail), inefficient, and platform-dependent. Also, re-running code from scratch can be highly time-consuming.
In this paper, we introduce a new notebook system, Elastic-Notebook, that offers live migration via checkpointing/restoration using a novel mechanism that is reliable, efficient, and platform-independent. Specifically, by observing all cell executions via transparent, lightweight monitoring, ElasticNotebook can find a reliable and efficient way (i.e., replication plan) for reconstructing the original session state, considering variable-cell dependencies, observed runtime, variable sizes, etc. To this end, our new graph-based optimization problem finds how to reconstruct all variables (efficiently) from a subset of variables that can be transferred across machines. We show that ElasticNotebook reduces end-to-end migration and restoration times by 85%-98% and 94%-99%, respectively, on a variety (i.e., Kaggle, JWST, and Tutorial) of notebooks with negligible runtime and memory overheads of <2.5% and <10%.
“Demonstration of the VeriEQL Equivalence Checker for Complex SQL Queries” [demo]
Pinhan Zhao, Yang He, Xinyu Wang, Yuepeng Wang
Abstract: The task of SQL query equivalence checking is important in various real-world applications (including query rewriting and automated grading) that involve complex queries with integrity constraints; yet, state-of-the-art techniques are very limited in their capability of reasoning about complex features (e.g., those that involve sorting, case statement, rich integrity constraints, etc.) in real-life queries. To the best of our knowledge, we propose the first SMT-based approach and its implementation, VeriEQL, capable of proving and disproving bounded equivalence of complex SQL queries. VeriEQL is based on a new logical encoding that models query semantics over symbolic tuples using the theory of integers with uninterpreted functions. It is simple yet highly practical — our comprehensive evaluation on over 20,000 benchmarks shows that VeriEQL outperforms all state-of-the-art techniques by more than one order of magnitude in terms of the number of benchmarks that can be proved or disproved. VeriEQL can also generate counterexamples that facilitate many downstream tasks (such as finding serious bugs in systems like MySQL and Apache Calcite).