 MENU
MENU 

Helping machine learning models identify objects in any pose
A new visual recognition approach improved a machine learning technique’s ability to both identify an object and how it is oriented in space, according to a study presented in October at the European Conference on Computer Vision in Milan, Italy.
Self-supervised learning is a machine learning approach that trains on unlabeled data, extending generalizability to real-world data. While it excels at identifying objects, a task called semantic classification, it may struggle to recognize objects in new poses.
This weakness quickly becomes a problem in situations like autonomous vehicle navigation, where an algorithm must assess whether an approaching car is a head-on collision threat or side-oriented and just passing by.
“Our work helps machines perceive the world more like humans do, paving the way for smarter robots, safer self-driving cars and more intuitive interactions between technology and the physical world,” said Stella Yu, a University of Michigan professor of computer science and engineering and senior author of the study.
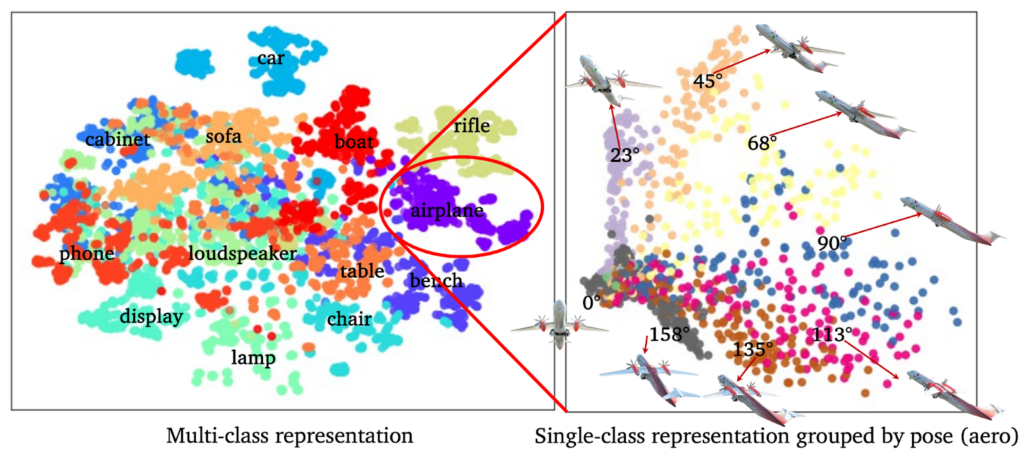
To help machines learn both object identities and poses, the research team developed a new self-supervised learning benchmark with problem setting, training and evaluation protocols along with a dataset of unlabeled image triplets for pose-aware representation learning.
The image triplets involve capturing three adjacent shots of the same object with slight camera pose changes, known as a smooth viewpoint trajectory. However, neither object labels (e.g. “car”) nor pose labels (e.g., frontal view) are provided.
This mimics robotic vision where the robot pans a camera as it moves around the environment. While the robot understands it is viewing the same object, it does not know what the object is or its pose.
Previous approaches typically managed regularization by mapping different views of the same object to the same feature at the final layer of a deep neural network. The new approach uses the mid-layer feature and imposes viewpoint trajectory regularization which instead maps three consecutive views of an object to a straight line in the feature space. The first strategy boosts pose estimation performance by 10-20%, whereas the second strategy further improves pose estimation by 4% without reducing semantic classification.
“More importantly, we map an image to a feature that encodes not only object identities but also object poses, and such a feature map can generalize better to images of novel objects the robot has never seen before,” said Jiayun Wang, a University of California Berkeley doctoral graduate of vision science and the Berkeley AI research lab and first author of the study.
This concept can be applied to uncover meaningful patterns in various types of related data, such as multichannel audio or time series. For instance, each snapshot of audio at a specific moment can be assigned a unique feature, while the entire sequence is mapped to a smooth feature trajectory that captures how things change continuously over time.
This research was supported in part by the National Science Foundation (2215542; 2313151) and Bosch gift funds to S. Yu at UC Berkeley and the University of Michigan.
Full citation: “Pose-aware self-supervised learning with viewpoint trajectory regularization,” Jiayun Wang, Yubei Chen, and Stella X. Yu, The 18th European Conference on Computer Vision ECCV (2024). DOI: 10.1007/978-3-031-72664-4_2