 MENU
MENU 

Nine papers by CSE researchers presented at CVPR 2023
Nine papers by researchers in the CSE Division of EECS at U-M have been accepted for presentation at the upcoming 2023 IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), the premier venue for the latest findings in computer vision. The conference is scheduled to take place June 18-22 in Vancouver, Canada. Topics covered by CSE researchers include object detection and segmentation, dynamic 3D modeling and reconstruction, language-guided visual learning, vision transformer architecture, and more.
The accepted papers are as follows (all CSE-affiliated authors in bold):
Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
Long Lian, Zhirong Wu, Stella X. Yu
Abstract: We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it. Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance. On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.

Cut and Learn for Unsupervised Object Detection and Instance Segmentation
Xudong Wang, Rohit Girdhar, Stella X. Yu, Ishan Misra
Abstract: We propose Cut-and-LEaRn (CutLER), a simple approach for training unsupervised object detection and segmentation models. We leverage the property of self-supervised models to ‘discover’ objects without supervision and amplify it to train a state-of-the-art localization model without any human labels. CutLER first uses our proposed MaskCut approach to generate coarse masks for multiple objects in an image, and then learns a detector on these masks using our robust loss function. We further improve performance by self-training the model on its predictions. Compared to prior work, CutLER is simpler, compatible with different detection architectures, and detects multiple objects. CutLER is also a zero-shot unsupervised detector and improves detection performance AP50 by over 2.7× on 11 benchmarks across domains like video frames, paintings, sketches, etc. With finetuning, CutLER serves as a low-shot detector surpassing MoCo-v2 by 7.3% APbox and 6.6% APmask on COCO when training with 5% labels.
HexPlane: A Fast Representation for Dynamic Scenes
Ang Cao, Justin Johnson
Abstract: Modeling and re-rendering dynamic 3D scenes is a challenging task in 3D vision. Many current approaches, building on NeRF, rely on implicit representations in this task, which are relatively slow because of tremendous MLP evaluations, constraining real-world applications. Surprisingly, we show that dynamic 3D scenes could be explicitly represented by six feature planes, leading to an elegant solution called HexPlane. As an explicit representation, HexPlane computes features of spacetime points by fusing vectors extracted from each plane, which is effective and highly efficient. With a tiny MLP, it provides impressive results for dynamic novel view synthesis, matching the image quality of prior work but improving training time by more than 100x. We conduct extensive ablations to investigate this representation and reveal its intriguing properties. Designed as a general representation, we hope HexPlane can broadly contribute to spacetime tasks and dynamic 3D applications.

Learning to Predict Scene-Level Implicit 3D from Posed RGBD Data
Nilesh Kulkarni, Linyi Jin, Justin Johnson, David F. Fouhey
Abstract: We introduce a method that can learn to predict scene-level implicit functions for 3D reconstruction from posed RGBD data. At test time, our system maps a previously unseen RGB image to a 3D reconstruction of a scene via implicit functions. While implicit functions for 3D reconstruction have often been tied to meshes, we show that we can train one using only a set of posed RGBD images. This setting may help 3D reconstruction unlock the sea of accelerometer+RGBD data that is coming with new phones. Our system, D2-DRDF, can match and sometimes outperform current methods that use mesh supervision and shows better robustness to sparse data.
Learning Visual Representations via Language-Guided Sampling
Mohamed El Banani, Karan Desai, Justin Johnson
Abstract: Although an object may appear in numerous contexts, we often describe it in a limited number of ways. Language allows us to abstract away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual representation learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach diverges from image-based contrastive learning by sampling view pairs using language similarity instead of hand-crafted augmentations or learned clusters. Our approach also differs from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than directly minimizing a cross-modal loss. Through a series of experiments, we show that language-guided learning yields better features than image-based and image-text representation learning approaches.
RGB no more: Minimally-decoded JPEG Vision Transformers
Jeongsoo Park, Justin Johnson
Abstract: Most neural networks for computer vision are designed to infer using RGB images. However, these RGB images are commonly encoded in JPEG before saving to disk; decoding them imposes an unavoidable overhead for RGB networks. Instead, our work focuses on training Vision Transformers (ViT) directly from the encoded features of JPEG. This way, we can avoid most of the decoding overhead, accelerating data load. Existing works have studied this aspect but they focus on CNNs. Due to how these encoded features are structured, CNNs require heavy modification to their architecture to accept such data. Here, we show that this is not the case for ViTs. In addition, we tackle data augmentation directly on these encoded features, which to our knowledge, has not been explored in-depth for training in this setting. With these two improvements — ViT and data augmentation — we show that our ViT-Ti model achieves up to 39.2% faster training and 17.9% faster inference with no accuracy loss compared to the RGB counterpart.
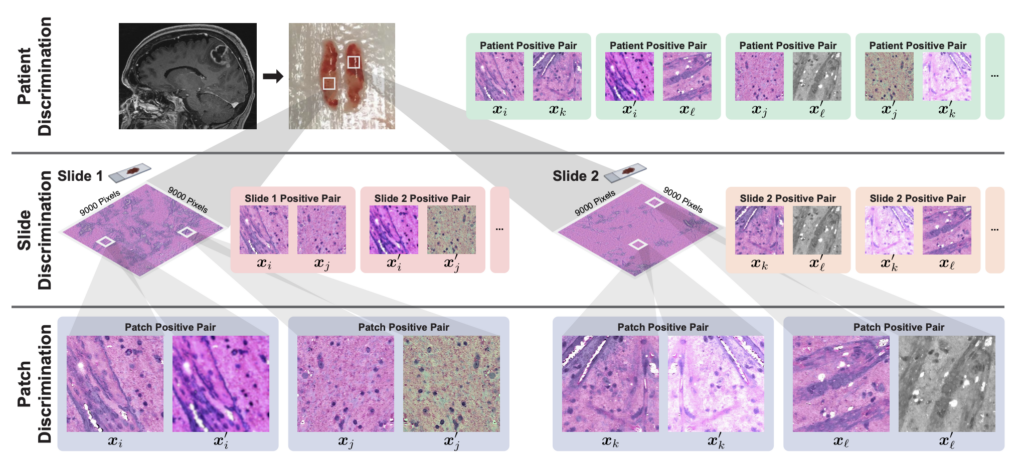
Hierarchical Discriminative Learning Improves Visual Representations of Biomedical Microscopy
Cheng Jiang, Xinhai Hou, Akhil Kondepudi, Asadur Chowdury, Christian W. Freudiger, Daniel A. Orringer, Honglak Lee, Todd C. Hollon
Abstract: Learning high-quality, self-supervised, visual representations is essential to advance the role of computer vision in biomedical microscopy and clinical medicine. Previous work has focused on self-supervised representation learning (SSL) methods developed for instance discrimination and applied them directly to image patches, or fields-of-view, sampled from gigapixel whole-slide images (WSIs) used for cancer diagnosis. However, this strategy is limited because it (1) assumes patches from the same patient are independent, (2) neglects the patient-slide-patch hierarchy of clinical biomedical microscopy, and (3) requires strong data augmentations that can degrade downstream performance. Importantly, sampled patches from WSIs of a patient’s tumor are a diverse set of image examples that capture the same underlying cancer diagnosis. This motivated HiDisc, a data-driven method that leverages the inherent patient-slide-patch hierarchy of clinical biomedical microscopy to define a hierarchical discriminative learning task that implicitly learns features of the underlying diagnosis. HiDisc uses a self-supervised contrastive learning framework in which positive patch pairs are defined based on a common ancestry in the data hierarchy, and a unified patch, slide, and patient discriminative learning objective is used for visual SSL. We benchmark HiDisc visual representations on two vision tasks using two biomedical microscopy datasets, and demonstrate that (1) HiDisc pretraining outperforms current state-of-the-art self-supervised pretraining methods for cancer diagnosis and genetic mutation prediction, and (2) HiDisc learns high-quality visual representations using natural patch diversity without strong data augmentations.
Perspective Fields for Single Image Camera Calibration
Linyi Jin, Jianming Zhang, Yannick Hold-Geoffroy, Oliver Wang, Kevin Matzen, Matthew Sticha, David F. Fouhey
Abstract: Geometric camera calibration is often required for applications that understand the perspective of the image. We propose perspective fields as a representation that models the local perspective properties of an image. Perspective Fields contain per-pixel information about the camera view, parameterized as an up vector and a latitude value. This representation has a number of advantages as it makes minimal assumptions about the camera model and is invariant or equivariant to common image editing operations like cropping, warping, and rotation. It is also more interpretable and aligned with human perception. We train a neural network to predict Perspective Fields and the predicted Perspective Fields can be converted to calibration parameters easily. We demonstrate the robustness of our approach under various scenarios compared with camera calibration-based methods and show example applications in image compositing.
MOVES: Manipulated Objects in Video Enable Segmentation
Richard E. L. Higgins, David F. Fouhey
Abstract: We present a method that uses manipulation to learn to understand the objects people hold and as well as hand-object contact. We train a system that takes a single RGB image and produces a pixel-embedding that can be used to answer grouping questions (do these two pixels go together) as well as hand-association questions (is this hand holding that pixel). Rather painstakingly annotate segmentation masks, we observe people in realistic video data. We show that pairing epipolar geometry with modern optical flow produces simple and effective pseudo-labels for grouping. Given people segmentations, we can further associate pixels with hands to understand contact. Our system achieves competitive results on hand and hand-held object tasks.
Additional research authored by EECS faculty appearing at CVPR
In addition to the above papers authored by CSE faculty, eight papers were presented by EECS faculty in the Department’s ECE Division. The ECE research being presented covers several state-of-the-art computer vision topics and applications, including audio-visual anomaly detection, robot navigation, video compression, and more.