 MENU
MENU 

Helping autonomous agents make smarter decisions in chaotic environments
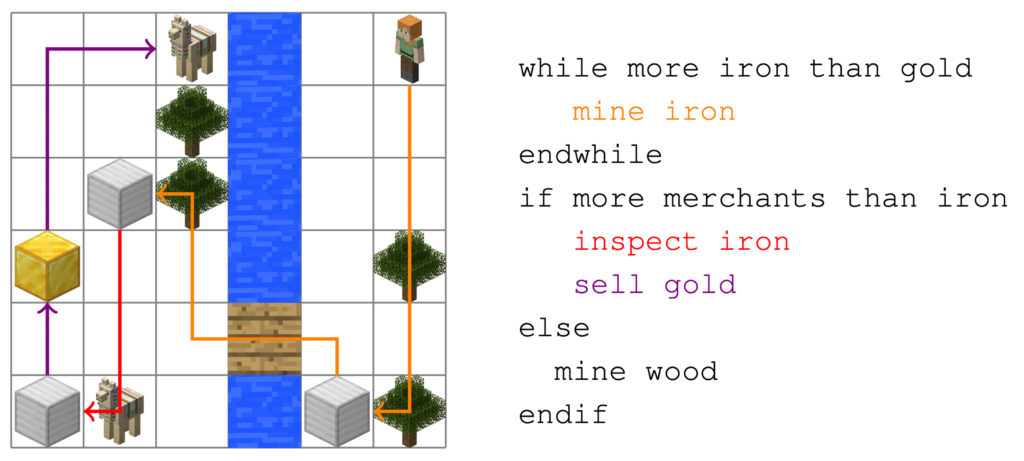
A new algorithm gives autonomous agents trained using Reinforcement Learning (RL) the ability to take in batches of multiple instructions at once and respond dynamically to changes in their surroundings. The architecture, with development led by PhD student Ethan Brooks and Prof. Satinder Singh, gives agents the capacity to re-do or skip instructions in response to changing situations, making them much more flexible when operating in chaotic settings.
Giving autonomous agents the ability to follow instructions in changing environments poses a lot of challenges. But a particularly significant limitation is the current inability of agents to accept long lists of instructions at once and deal with them without a helping hand from humans. Being able to assess which of its list of objectives are satisfied as the agent proceeds through its environment can help it learn to finish tasks more efficiently.
“A lot of the work in this area looks at single discrete instructions,” Brooks explains, “go to the red ball, get the key and then open the door – things like that. We’re interested in a subset of this where you’ll have a long sequence of instructions, as many as 50, that have to be performed in some order. This order is not necessarily one after the next.”
This is where two cases of control flow come into play. Agents have to respond to changing expectations, both from their surroundings and from the instructions they’re given. In the case of control flow from instructions, things like conditional branches and loops can provide an explicit need to skip forward over parts of the instructions or return to previously completed or skipped steps. Similarly, dynamic environments can require an agent to do instructions over again whose effects have been perturbed, or opportunistically skip instructions whose effects are already present.
“The world is chaotic,” says Brooks. “When in real life can you set out to perform a list of things in sequence without any interruption from the outside world?”
This ability to respond to chaotic inputs will be particularly important as these learning agents find more uses in real-world applications. While currently RL models aren’t widely deployed in the field of robotics, their ability to learn from their surroundings with only a goal to guide them can fill a large need in tasks like autonomous driving and remote exploration.
“Robots are fairly deterministic in their behavior,” Brooks says. “If a stochastic event occurs, the robot will have to ring an alarm and have a human step in.”
The researchers’ new findings on control flow represent an important step toward making these models viable in dynamic situations. A key innovation in their approach is how the agents approach figuring out what their next step will be. As time passes in a simulation, the agent has to make two decisions at each step – what action to take in the real world, and where to look for their next instruction in the list. Rather than read the list naively in order, many RL agents assign likelihood values to a certain range of instructions, and agents learn over time to find markers in instructions and tie those to different needs and situations.
Often, however, these models only train agents on very short lists of instructions, leaving them unprepared to deal with the possibilities that come from longer sequences later. A typical failure of models designed this way is that they’ll look ahead only a short distance when they reach a decision point, finding themselves in the middle of instructions that should have been enclosed in a conditional statement they haven’t met. At this point their behavior can become random or sporadic, as their goals stop aligning with the conditions around them.
Brooks and collaborators instead train their models to expect big jumps in long lists of instructions, even when the initial training data is still small. This way, if the agent encounters a decision to be made, it’s trained to look through essentially the whole list of instructions available to it and identify steps that are the most likely related to its situation.
“At the end of the day we want to apply RL in settings where we tell agents what to do,” says Brooks, “and the idea of issuing a large sequence of commands, as opposed to issuing a command and waiting for the robot to perform it, has a lot of import.”
The team tested their architecture’s ability to learn the two different types of control flow in two different environments, inspired by StarCraft and Minecraft. They showed that their approach could be generalized to new lists of instructions longer than what it was trained on, with performance unmatched by four baseline comparison architectures.
In continuing this work, the team plans to expand the way their agents can respond to changing inputs by exploring the bridge between RL and natural language processing.
“My advisor and I have always wanted to keep moving in the direction of less structure, and fewer assumptions about the inputs our agents are given,” says Brooks. “We’re continuing to investigate the marriage between RL and natural language, and we’ve shifted perspective to looking at pre-trained language models and how they can relate to reinforcement learning.”
This project, titled “Reinforcement Learning of Implicit and Explicit Control Flow Instructions,” was published at the 2021 International Conference on Machine Learning, co-authored by Brooks, Baveja, and Janarthanan Rajendran from U-M CSE and Richard L. Lewis from the U-M Departments of Psychology and Linguistics.