 MENU
MENU 

Ten papers by CSE researchers presented at EMNLP 2023
Ten papers by CSE researchers are being presented in the main track of the 2023 Conference on Empirical Methods in Natural Language Processing (2023), which is taking place December 6-10 in Singapore. An additional ten papers by CSE authors have been published in the Findings track of the conference.
Organized by the Association for Computational Linguistics (ACL) Special Interest Group on Linguistic Data (SIGDAT), EMNLP has been held annually since 1996 and is one of the top international conferences on natural language processing (NLP) and artificial intelligence (AI) more broadly.
CSE-affiliated authors are presenting work on various groundbreaking topics related to NLP, from detecting bias in folktales and commonly used AI models to assessing vision-language models’ ability to perceive optical illusions, and beyond.
The papers by CSE authors are as follows, with the names of researchers affiliated with CSE in bold:
Main Conference Papers
“Cross-Cultural Analysis of Human Values, Morals, and Biases in Folk Tales”
Winston Wu, Lu Wang, Rada Mihalcea
Abstract: Folk tales are strong cultural and social influences in children’s lives, and they are known to teach morals and values. However, existing studies on folk tales are largely limited
to European tales. In our study, we compile a large corpus of over 1,900 tales originating from 27 diverse cultures across six continents. Using a range of lexicons and correlation analyses, we examine how human values, morals, and gender biases are expressed in folk tales across cultures. We discover differences between cultures in prevalent values and morals, as well as cross-cultural trends in problematic gender biases. Furthermore, we find trends of reduced value expression when examining public-domain fiction stories, extrinsically validate our analyses against the multicultural Schwartz Survey of Cultural Values, and find traditional gender biases associated with values, morals, and agency. This large-scale cross-cultural study of folk tales paves the way for future studies on how literature influences and reflects cultural norms.
“Bridging the Digital Divide: Performance Variation across Socio-Economic Factors in Vision-Language Models”
Joan Nwatu, Oana Ignat, Rada Mihalcea
Abstract: Despite the impressive performance of current AI models reported across various tasks, performance reports often do not include evaluations of how these models perform on the specific groups that will be impacted by these technologies. Among the minority groups under-represented in AI, data from low-income households are often overlooked in data collection and model evaluation. We evaluate the performance of a state-of-the-art vision-language model (CLIP) on a geo-diverse dataset containing household images associated with different income values (Dollar Street) and show that performance inequality exists among households of different income levels. Our results indicate that performance for the poorer groups is consistently lower than the wealthier groups across various topics and countries. We highlight insights that can help mitigate these issues and propose actionable steps for economic-level inclusive AI development. The code for this project is available on Github.

“Task-Adaptive Tokenization: Enhancing Long-Form Text Generation Efficacy in Mental Health and Beyond”
Siyang Liu, Naihao Deng, Sahand Sabour, Yilin Jia, Minlie Huang, Rada Mihalcea
Abstract: We propose task-adaptive tokenization as a way to adapt the generation pipeline to the specifics of a downstream task and enhance long-form generation in mental health. Inspired by insights from cognitive science, our task-adaptive tokenizer samples variable segmentations from multiple outcomes, with sampling probabilities optimized based on task-specific data. We introduce a strategy for building a specialized vocabulary and introduce a vocabulary merging protocol that allows for the integration of task-specific tokens into the pre-trained model’s tokenization step. Through extensive experiments on psychological question-answering tasks in both Chinese and English, we find that our task-adaptive tokenization approach brings a significant improvement in generation performance while using up to 60% fewer tokens. Preliminary experiments point to promising results when using our tokenization approach with very large language models.
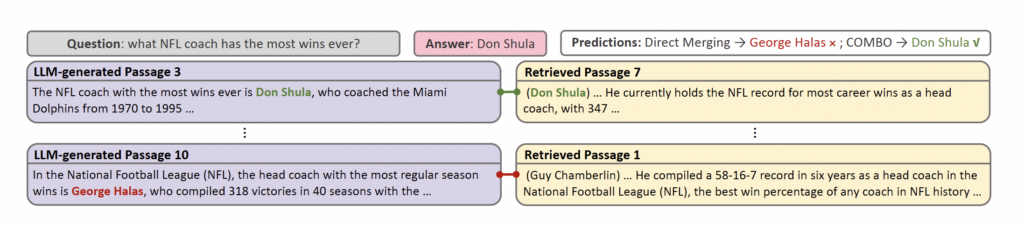
“Merging Generated and Retrieved Knowledge for Open-Domain QA”
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, Lu Wang
Abstract: Open-domain question answering (QA) systems are often built with retrieval modules. However, retrieving passages from a given source is known to suffer from insufficient knowledge coverage. Alternatively, prompting large language models (LLMs) to generate contextual passages based on their parametric knowledge has been shown to improve QA performance. Yet, LLMs tend to “hallucinate” content that conflicts with the retrieved knowledge. Based on the intuition that answers supported by both sources are more likely to be correct, we propose COMBO, a Compatibility-Oriented knowledge Merging for Better Open-domain QA framework, to effectively leverage the two sources of information. Concretely, we match LLM-generated passages with retrieved counterparts into compatible pairs, based on discriminators trained with silver compatibility labels. Then a Fusion-in-Decoder-based reader model handles passage pairs to arrive at the final answer. Experiments show that COMBO outperforms competitive baselines on three out of four tested open-domain QA benchmarks. Further analysis reveals that our proposed framework demonstrates greater efficacy in scenarios with a higher degree of knowledge conflicts.
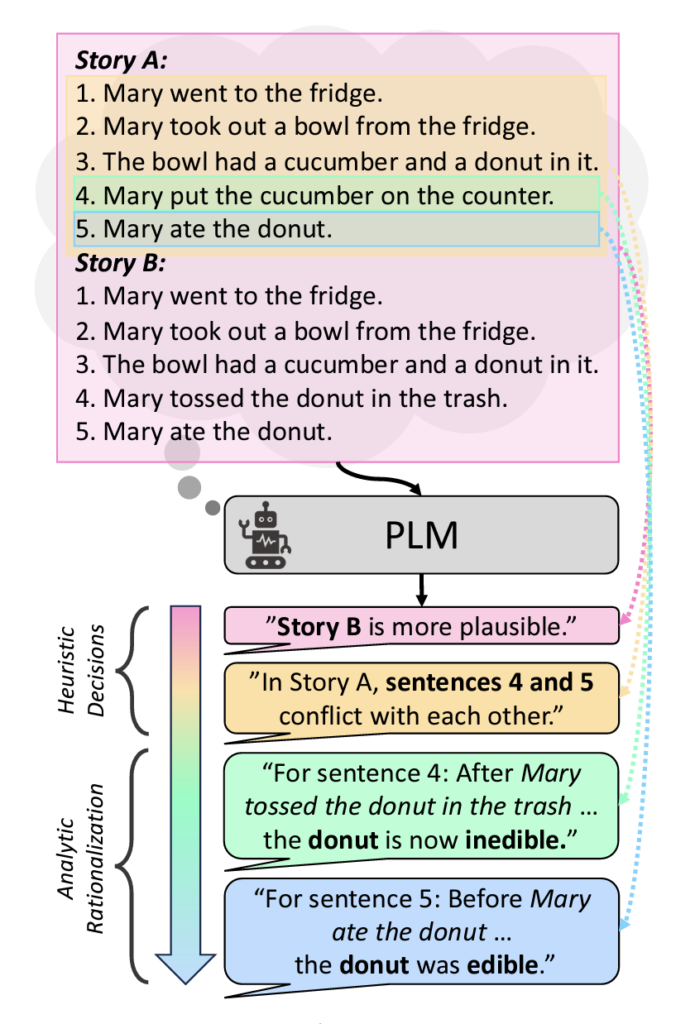
“From Heuristic to Analytic: Cognitively Motivated Strategies for Coherent Physical Commonsense Reasoning”
Zheyuan Zhang, Shane Storks, Fengyuan Hu, Sungryull Sohn, Moontae Lee, Honglak Lee, Joyce Chai
Abstract: Pre-trained language models (PLMs) have shown impressive performance in various language tasks. However, they are prone to spurious correlations, and often generate illusory information. In real-world applications, PLMs should justify decisions with formalized, coherent reasoning chains, but this challenge remains under-explored. Cognitive psychology theorizes that humans are capable of utilizing fast and intuitive heuristic thinking to make decisions based on past experience, then rationalizing the decisions through slower and deliberative analytic reasoning. We incorporate these interlinked dual processes in fine-tuning and in-context learning with PLMs, applying them to two language understanding tasks that require coherent physical commonsense reasoning. We show that our proposed Heuristic-Analytic Reasoning (HAR) strategies drastically improve the coherence of rationalizations for model decisions, yielding state-of-the-art results on Tiered Reasoning for Intuitive Physics (TRIP). We also find that this improved coherence is a direct result of more faithful attention to relevant language context in each step of reasoning. Our findings suggest that human-like reasoning strategies can effectively improve the coherence and reliability of PLM reasoning.
“A Picture is Worth a Thousand Words: Language Models Plan from Pixels”
Anthony Liu, Lajanugen Logeswaran, Sungryull Sohn, Honglak Lee
Abstract: Planning is an important capability of artificial agents that perform long-horizon tasks in real-world environments. In this work, we explore the use of pre-trained language models (PLMs) to reason about plan sequences from text instructions in embodied visual environments. Prior PLM based approaches for planning either assume observations are available in the form of text (e.g., provided by a captioning model), reason about plans from the instruction alone, or incorporate information about the visual environment in limited ways (such as a pre-trained affordance function). In contrast, we show that PLMs can accurately plan even when observations are directly encoded as input prompts for the PLM. We show that this simple approach outperforms prior approaches in experiments on the ALFWorld and VirtualHome benchmarks.
“TOD-Flow: Modeling the Structure of Task-Oriented Dialogues”
Sungryull Sohn, Yiwei Lyu, Anthony Liu, Lajanugen Logeswaran, Dong-Ki Kim, Dongsub Shim, Honglak Lee
Abstract: Task-Oriented Dialogue (TOD) systems have become crucial components in interactive artificial intelligence applications. While recent advances have capitalized on pre-trained language models (PLMs), they exhibit limitations regarding transparency and controllability. To address these challenges, we propose a novel approach focusing on inferring the TOD-flow graph from dialogue data annotated with dialog acts, uncovering the underlying task structure in the form of a graph. The inferred TOD-flow graph can be easily integrated with any dialogue model to improve its prediction performance, transparency, and controllability. Our TOD-flow graph learns what a model can, should, and should not predict, effectively reducing the search space and providing a rationale for the model’s prediction. We show that the proposed TOD-flow graph better resembles human-annotated graphs compared to prior approaches. Furthermore, when combined with several dialogue policies and end-to-end dialogue models, we demonstrate that our approach significantly improves dialog act classification and end-to-end response generation performance in the MultiWOZ and SGD benchmarks.
“All Things Considered: Detecting Partisan Events from News Media with Cross-Article Comparison”
Yujian Liu, Xinliang Frederick Zhang, Kaijian Zou, Ruihong Huang, Nicholas Beauchamp, Lu Wang
Abstract: Public opinion is shaped by the information news media provide, and that information in turn may be shaped by the ideological preferences of media outlets. But while much attention has been devoted to media bias via overt ideological language or topic selection, a more unobtrusive way in which the media shape opinion is via the strategic inclusion or omission of partisan events that may support one side or the other. We develop a latent variable-based framework to predict the ideology of news articles by comparing multiple articles on the same story and identifying partisan events whose inclusion or omission reveals ideology. Our experiments first validate the existence of partisan event selection, and then show that article alignment and cross-document comparison detect partisan events and article ideology better than competitive baselines. Our results reveal the high-level form of media bias, which is present even among mainstream media with strong norms of objectivity and nonpartisanship. The code and dataset for this project are available on Github.

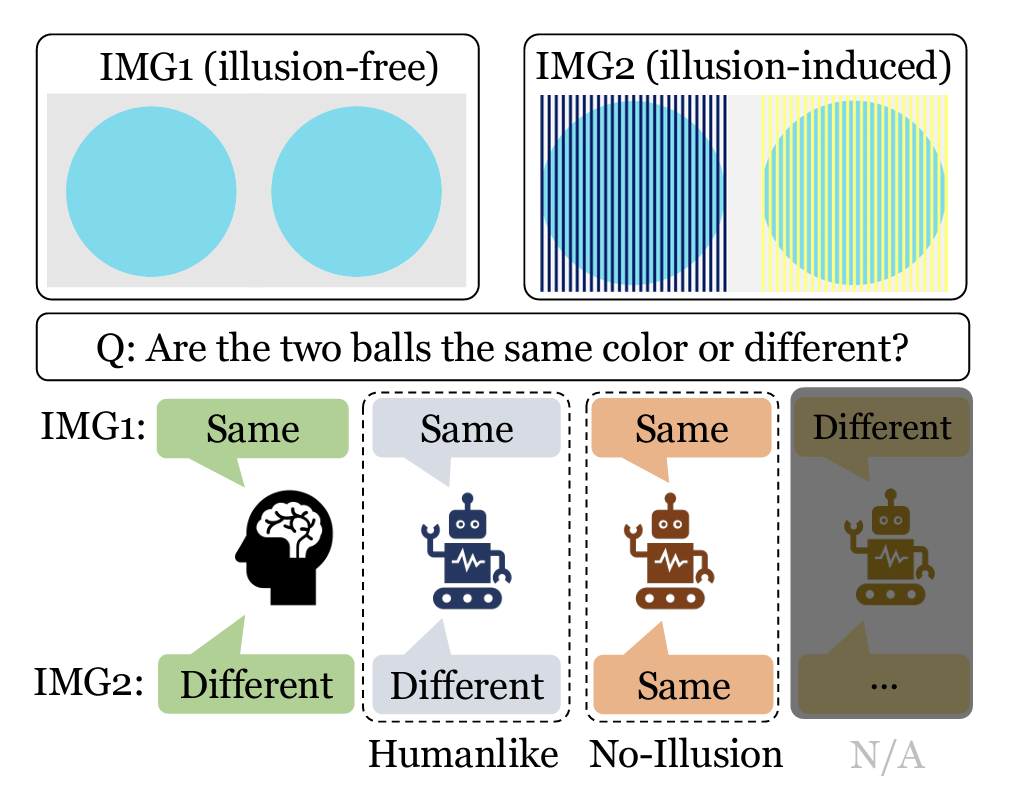
“Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?”
Yichi Zhang, Jiayi Pan, Yuchen Zhou, Rui Pan, Joyce Chai
Abstract: Vision-Language Models (VLMs) are trained on vast amounts of data captured by humans emulating our understanding of the world. However, known as visual illusions, human’s perception of reality isn’t always faithful to the physical world. This raises a key question: do VLMs have the similar kind of illusions as humans do, or do they faithfully learn to represent reality? To investigate this question, we build a dataset containing five types of visual illusions and formulate four tasks to examine visual illusions in state-of-the-art VLMs. Our findings have shown that although the overall alignment is low, larger models are closer to human perception and more susceptible to visual illusions. Our dataset and initial findings will promote a better understanding of visual illusions in humans and machines and provide a stepping stone for future computational models that can better align humans and machines in perceiving and communicating about the shared visual world. The code and data for this project are available on Github.
“Do LLMs Understand Social Knowledge? Evaluating the Sociability of Large Language Models with SocKET Benchmark”
Minje Choi, Jiaxin Pei, Sagar Kumar, Chang Shu, David Jurgens
Abstract: Large language models (LLMs) have been shown to perform well at a variety of syntactic, discourse, and reasoning tasks. While LLMs are increasingly deployed in many forms including conversational agents that interact with humans, we lack a grounded benchmark to measure how well LLMs understand \textit{social} language. Here, we introduce a new theory-driven benchmark, SocKET, that contains 58 NLP tasks testing social knowledge which we group into five categories: humor & sarcasm, offensiveness, sentiment & emotion, and trustworthiness. In tests on the benchmark, we demonstrate that current models attain only moderate performance but reveal significant potential for task transfer among different types and categories of tasks, which were predicted from theory. Through zero-shot evaluations, we show that pretrained models already possess some innate but limited capabilities of social language understanding and training on one category of tasks can improve zero-shot testing on others. Our benchmark provides a systematic way to analyze model performance on an important dimension of language and points to clear room for improvement to build more socially-aware LLMs. The associated resources for this project are available on Github.
Findings Track Papers
“Beyond Good Intentions: Reporting the Research Landscape of NLP for Social Good”
Fernando Adauto, Zhijing Jin, Bernhard Schölkopf, Tom Hope, Mrinmaya Sachan, Rada Mihalcea
“VERVE: Template-based ReflectiVE Rewriting for MotiVational IntErviewing”
Do Min, Verónica Pérez-Rosas, Ken Resnicow, Rada Mihalcea
“Hi-ToM: A Benchmark for Evaluating Higher-Order Theory of Mind Reasoning in Large Language Models”
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, Naihao Deng
“You Are What You Annotate: Towards Better Models through Annotator Representations”
Naihao Deng, Xinliang Frederick Zhang, Siyang Liu, Winston Wu, Lu Wang, Rada Mihalcea
“Language Guided Visual Question Answering: Elevate Your Multimodal Language Model Using Knowledge-Enriched Prompts”
Deepanway Ghosal, Navonil Majumder, Roy Lee, Rada Mihalcea, Soujanya Poria
“GRACE: Discriminator-Guided Chain-of-Thought Reasoning”
Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, Lu Wang
“Crossing the Aisle: Unveiling Partisan and Counter-Partisan Events in News Reporting”
Kaijian Zou, Xinliang Frederick Zhang, Winston Wu, Nicholas Beauchamp, Lu Wang
“When it Rains, it Pours: Modeling Media Storms and the News Ecosystem”
Benjamin Litterer, David Jurgens, Dallas Card
“MetaReVision: Meta-Learning with Retrieval for Visually Grounded Compositional Concept Acquisition”
Guangyue Xu, Parisa Kordjamshidi, Joyce Chai
“Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?”
Emily Yuwei Bao, Keunwoo Yu, Yichi Zhang, Shane Storks, Itamar Bar-Yossef, Alex de la Iglesia, Megan Su, Xiao Zheng, Joyce Chai