 MENU
MENU 

Best Paper to give robots more planning foresight
A project led by PhD student Alphonsus Adu-Bredu and Prof. Chad Jenkins has been recognized with the Best Paper Award on Mobile Manipulation at the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems. In “Probabilistic Inference in Planning for Partially Observable Long Horizon Problems,” the researchers propose a method to give robots more foresight in planning and executing lists of goals.
Robotics research has long envisioned robots capable of performing household tasks. But robots capable of operating this way would be faced with a number of challenges current machines can’t handle – in particular, managing “to do lists” of their goals that extend well into the future and managing uncertainties about its ever-changing surroundings.
The key shortcoming here is that robots are generally unable to adapt to changing conditions as they work through a set of tasks. Given a room that exists in one configuration, it’s now possible to have a robot plan a course of action based on that setting – but once they enter the dynamic and fluid world of humans, they’ll have to be able to handle losing sight of their goals at times (literally). Additional challenges arise when the robot itself changes the environment, or loses track of how its joints are configured.
Adu-Bredu, Jenkins, and co-authors Nikhil Devraj, Pin-Han Lin, and Dr. Zhen Zeng propose SHY-COBRA as an answer to this shortcoming. Short for Satisfying HYbrid COnstraints with Belief pRopAgation, the framework provides a means to plan while faced with different sources of uncertainty.
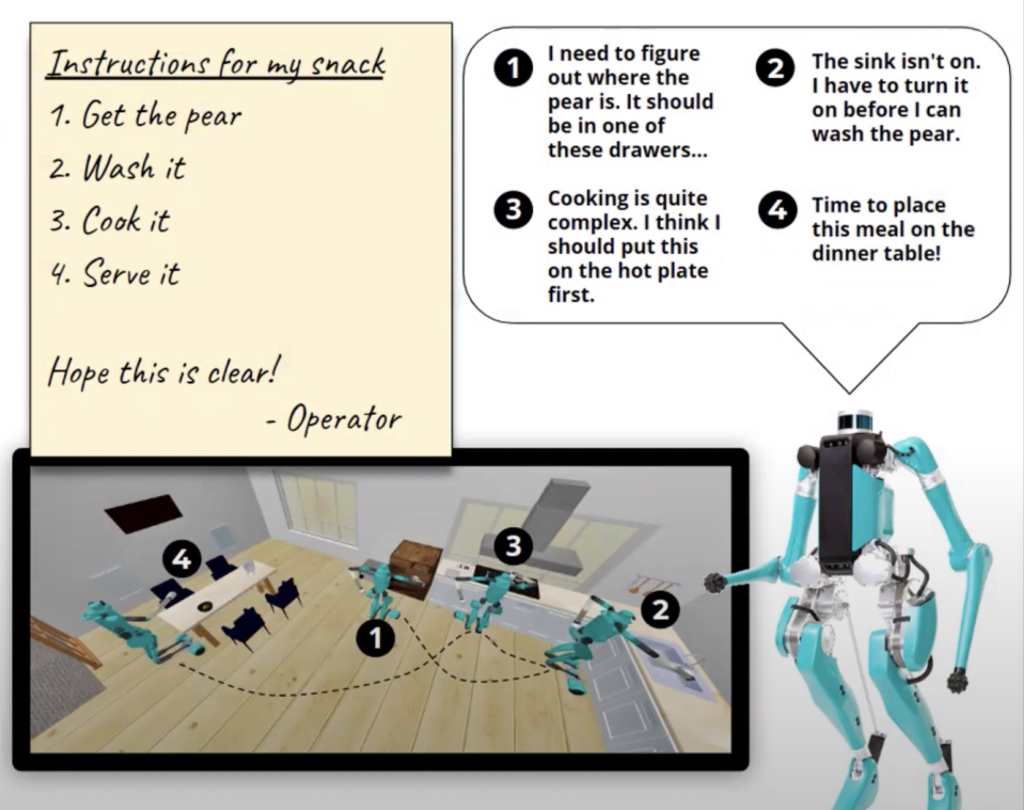
SHY-COBRA initially provides the robot with a high-level goal and a prior belief, or a ground truth set of observations about its surroundings. Given the goal and this starting environment, it makes its first plan on how to get the task done. If the actions in the plan are executed successfully, the robot is done. Each time an action fails to satisfy the desired effect, it re-assesses its surroundings to update its belief and devise a new plan.
For example, if the robot is tasked with cutting up a pear, it starts with the objective that it needs to find and pick up a pear. Its initial belief might be that there’s a pear waiting in a certain kitchen drawer. If the robot checks this drawer and finds no pear there, then it has to update its belief with this observation and start again. Now it might try a different drawer, repeating until it finds what it’s looking for.
Under the hood, SHY-COBRA creates what the authors call a plan skeleton of high-level, symbolic actions that need to be performed in order each time the robot updates its belief with new observations. This skeleton is used to compose a graph called a constraint network made up of variable and constraint nodes that are initialized with the starting belief. The constraints include measurable things like the robot’s joint configuration, object pose, grasp pose, and joint trajectory. Nonparametric belief propagation is then used to pass messages between the nodes until they converge around a set of beliefs that satisfy all of the constraints. These satisfied constraints then provide parameter values that can be assigned to the plan skeleton, which can in turn be interpreted as concrete actions for the robot to take.
The team examined the performance of SHY-COBRA on tasks under conditions of increasing object pose estimation and joint configuration uncertainty. Overall, SHY-COBRA makes fewer errors and replanning calls than comparable software, and as a result spends less time planning.
Going forward, says Adu-Bredu, the team sees room for improvement on two major fronts. Currently, SHY-COBRA is time-consuming to set up manually because it requires tuning of a number of hyperparameters. A better model down the road would be able to learn from data or experience and cut down on manual set up. Additionally, the current model’s planning time, despite being faster than previous models, still faces long planning time for the most uncertain scenarios it faced.